万盛华
南京大学LAMDA组博士研究生
专注于强化学习及其在现实世界中的应用,主要研究sim2real问题,包括策略诱导的世界模型学习、跨模态观测下的世界模型学习以及噪声环境中的学习控制。

专注于强化学习及其在现实世界中的应用,主要研究sim2real问题,包括策略诱导的世界模型学习、跨模态观测下的世界模型学习以及噪声环境中的学习控制。
探索强化学习的前沿领域
研究如何通过学习世界模型来预测环境动态,从而减少对真实环境交互的依赖,提高样本效率。
探索在不同感知模态(如视觉、触觉等)下如何构建统一的世界模型,实现多模态信息的融合与利用。
研究在存在感知噪声和执行噪声的环境中,如何设计鲁棒的学习算法,使智能体能够有效学习和决策。
精选论文与研究成果
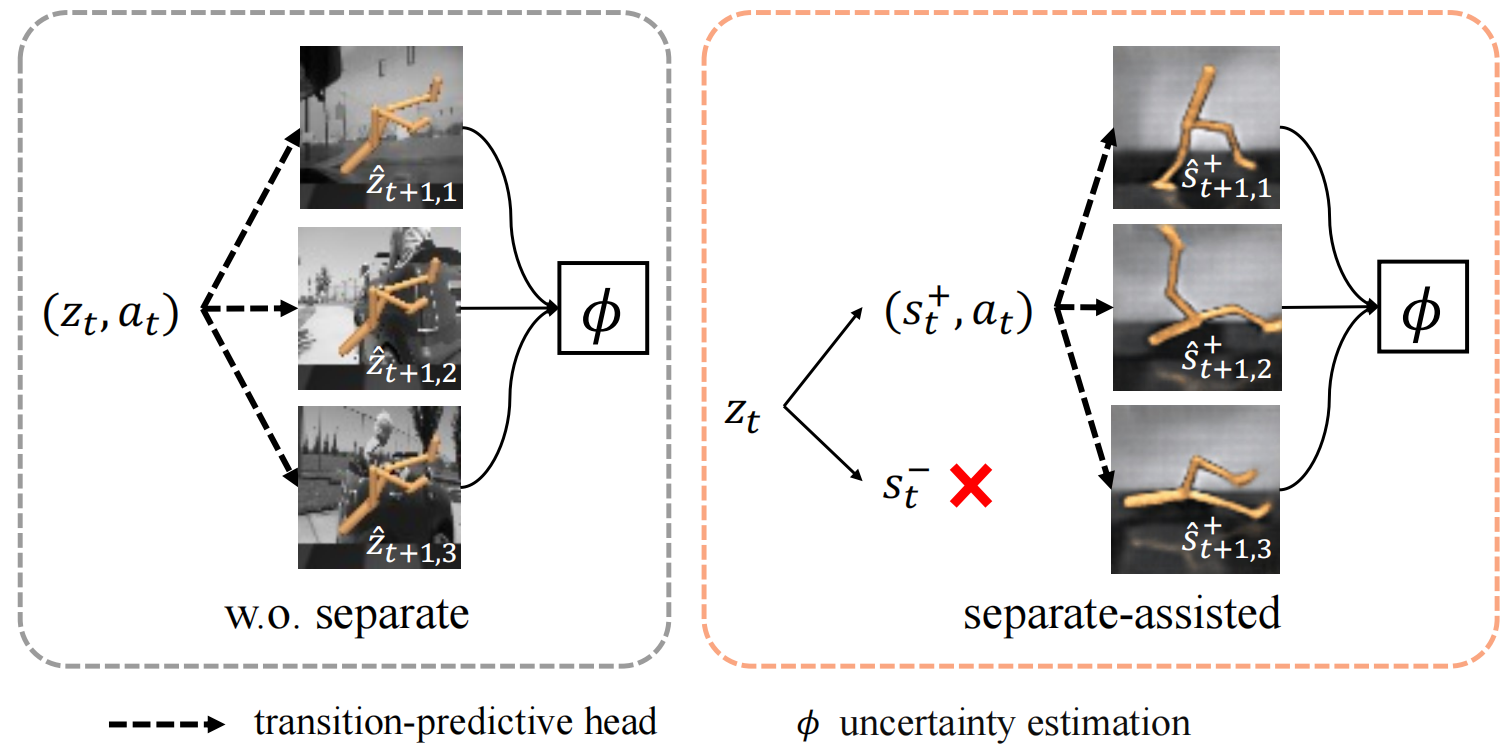
我们提出了一个名为Separation-assisted eXplorer (SeeX)的双层优化框架。在内层优化中,SeeX训练一个分离的世界模型来提取外生和内生信息,最小化不确定性以确保任务相关性。在外层优化中,它学习一个策略在内生状态空间生成的想象轨迹上最大化任务相关的不确定性。
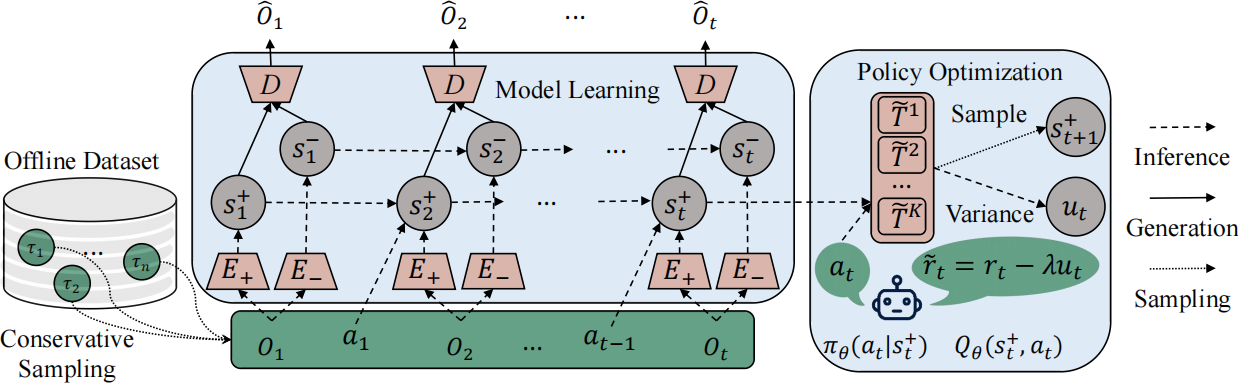
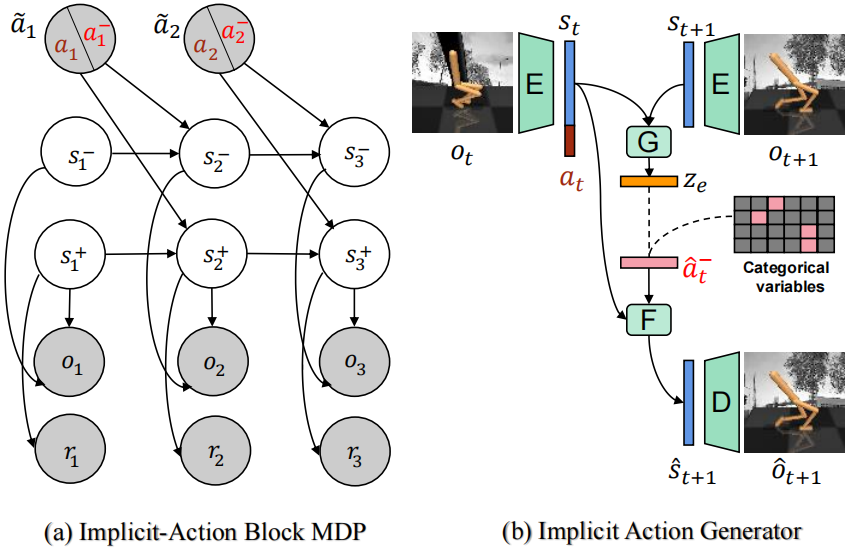
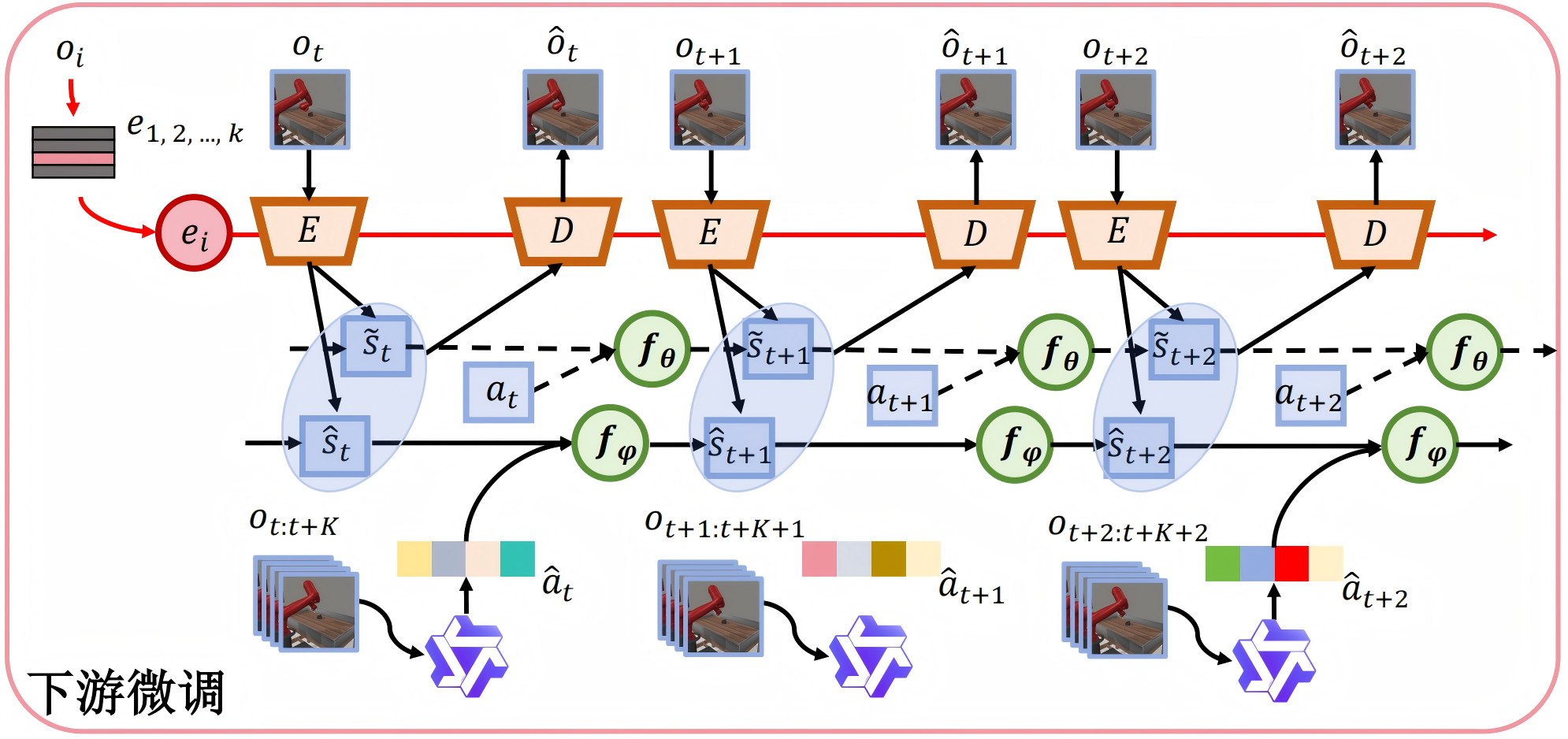
我们提出了MAPO(基于多模态大模型生成动作的视频预训练),利用视觉语言模型生成详细的语义动作描述,建立带有因果解释的动作-状态关联。实验结果表明,MAPO显著提高了在DeepMind Control Suite和Meta-World上的性能,特别是在长时程任务中。

在这篇综述中,我们全面回顾了强化学习文献中的奖励建模技术。我们首先概述了奖励建模的背景和基础知识。接着,我们介绍了最新的奖励建模方法,并根据来源、机制和奖励学习范式进行分类。在此基础上,我们讨论了这些奖励建模技术的各种应用,并回顾了评估奖励模型的方法。
学术与研究成就的认可
