Deep Bimodal Regression for Apparent Personality Analysis
 |
Authors
Abstract
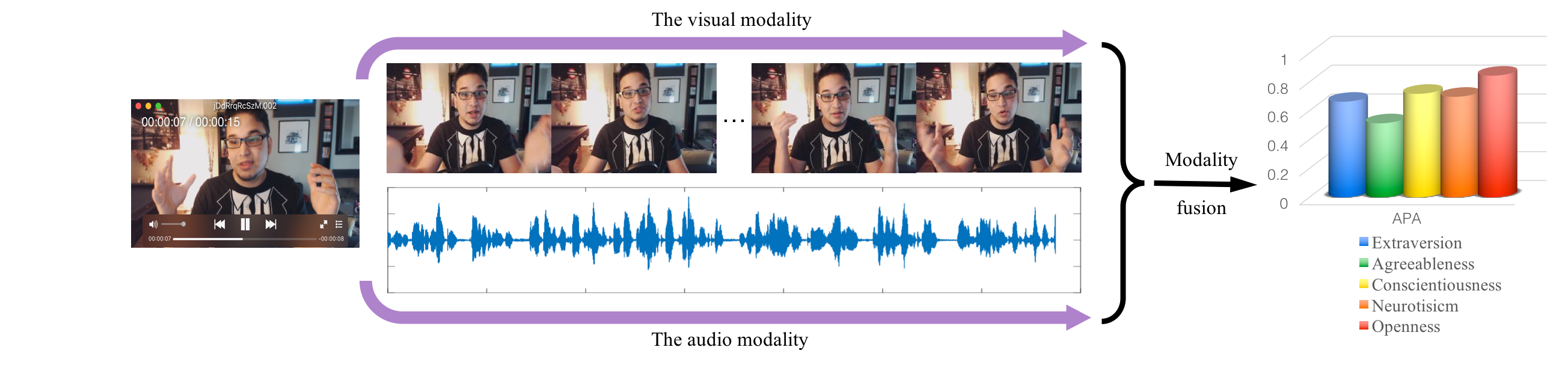
Apparent personality analysis (APA) is an important problem of personality computing, and furthermore, automatic APA becomes a hot and challenging topic in computer vision and multimedia. In this paper, we propose a deep learning solution to APA from short video sequences. In order to capture rich information from both the visual and audio modality of videos, we tackle these tasks with our Deep Bimodal Regression (DBR) framework. In DBR, for the visual modality, we modify the traditional convolutional neural networks for exploiting important visual cues. In addition, taking into account the model efficiency, we extract audio representations and build a linear regressor for the audio modality. For combining the complementary information from the two modalities, we ensemble these predicted regression scores by both early fusion and late fusion. Finally, based on the proposed framework, we come up with a solution for the Apparent Personality Analysis competition track in the ChaLearn Looking at People challenge in association with ECCV 2016. Our DBR is the winner (first place) of this challenge with 86 registered participants. Beyond the competition, we further investigate the performance of different loss functions in our visual models, and prove non-convex loss functions for regression are optimal on the human-labeled video data.
Highlights
Proposed Descriptor Aggregation Network (DAN) and DAN+
 |
In the visual modality of DBR, the main deep CNN models are modified based on our previous work, which are called Descriptor Aggregation Networks (DANs). What distinguishes DAN from the traditional CNN is: the fully connected layers are discarded, and replaced by both average- and max-pooling following the last convolution layers (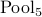 ). Meanwhile, each pooling operation is followed by the standard
). Meanwhile, each pooling operation is followed by the standard 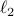 -normalization. After that, the obtained two 512-d feature vectors are concatenated as the final image representation. Thus, in DAN, the deep descriptors of the last convolution layers are aggregated as a single visual feature. Finally, because APA is a regression problem, a regression (fc+sigmoid) layer is added for end-to-end training.
-normalization. After that, the obtained two 512-d feature vectors are concatenated as the final image representation. Thus, in DAN, the deep descriptors of the last convolution layers are aggregated as a single visual feature. Finally, because APA is a regression problem, a regression (fc+sigmoid) layer is added for end-to-end training.
Because DAN has no fully connected layers, it will bring several benefits, such as reducing the model size, reducing the dimensionality of the final feature, and accelerating the model training. Moreover, the model performance of DAN is better than traditional CNNs with the fully connected layers.
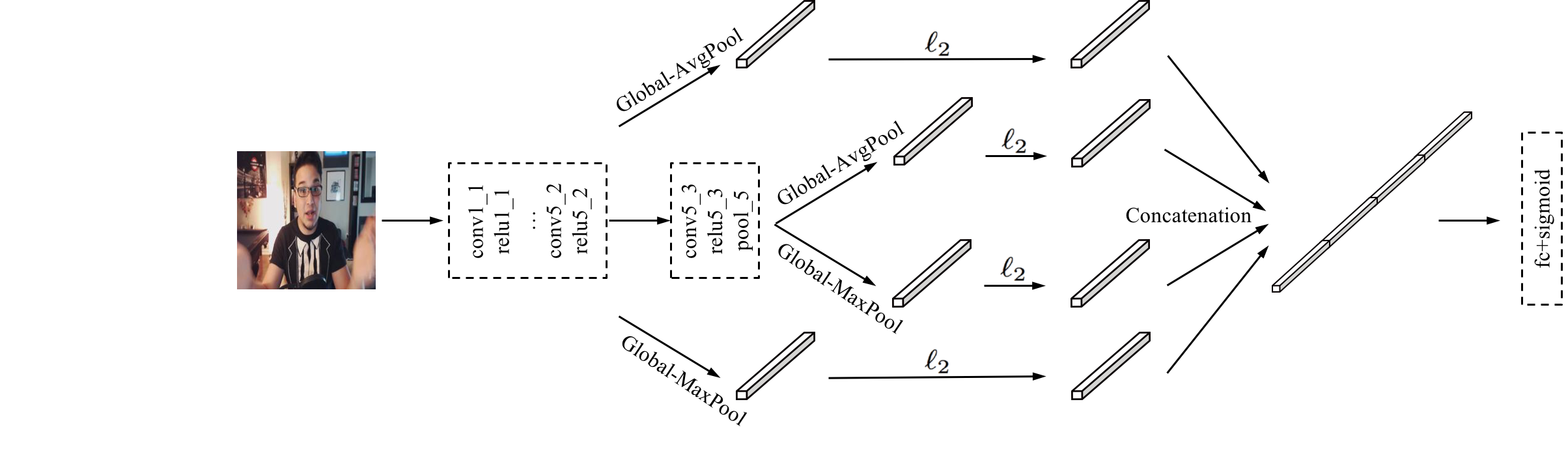 |
For further improving the regression performance of DAN, the ensemble of multiple layers is employed. Specifically, the deep convolutional descriptors of 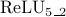 are also incorporated in the aforementioned aggregation approach. Thus, the final image feature is a 2048-d vector. We call this end-to-end deep regression network as “DAN+”.
are also incorporated in the aforementioned aggregation approach. Thus, the final image feature is a 2048-d vector. We call this end-to-end deep regression network as “DAN+”.
Results of the ChaLearn LAP Challenge
Development Phase
 |
In this table, we present the main results of both the visual and audio modality in the Development phase. Note that, during the competition, we employed the 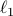 loss function for training all the visual deep convolutional neural networks, including VGG-Face, ResNet, DAN and DAN+.
loss function for training all the visual deep convolutional neural networks, including VGG-Face, ResNet, DAN and DAN+.
For the visual modality, we also fine-tune the available VGG-Face model on the competition data for comparison. As shown in that table, the regression accuracy of DAN (0.9100) is better than VGG-Face (0.9072) with the traditional VGG-16 architecture, and even better than Residual Networks (0.9080). Meanwhile, because DAN has no traditional fully connected (FC) layers, the number of the DAN parameters is only 14.71M, which is much less than 134.28M of VGG-16 and 58.31M of ResNet. It will bring storage efficiency. Meanwhile, without the parameter redundant FC layers, the inference speed of DAN and DAN+ is faster than both VGG-based models and ResNet. For each video, the personality traits prediction time is about 0.39s, which makes real time prediction possible.
In addition, from the results of the first and second epoch, we can find the regression accuracy becomes lower when the training epochs increase, which might be overfitting. Thus, we stop training after the second epoch. Then, we average the predicted scores of these two epochs as the epoch fusion. The performance of the epoch fusion is better than that of single epoch. Therefore, the averaged regression scores of the epoch fusion are the predictions of the visual modality, which is the early fusion in DBR.
Final Evaluation Phase
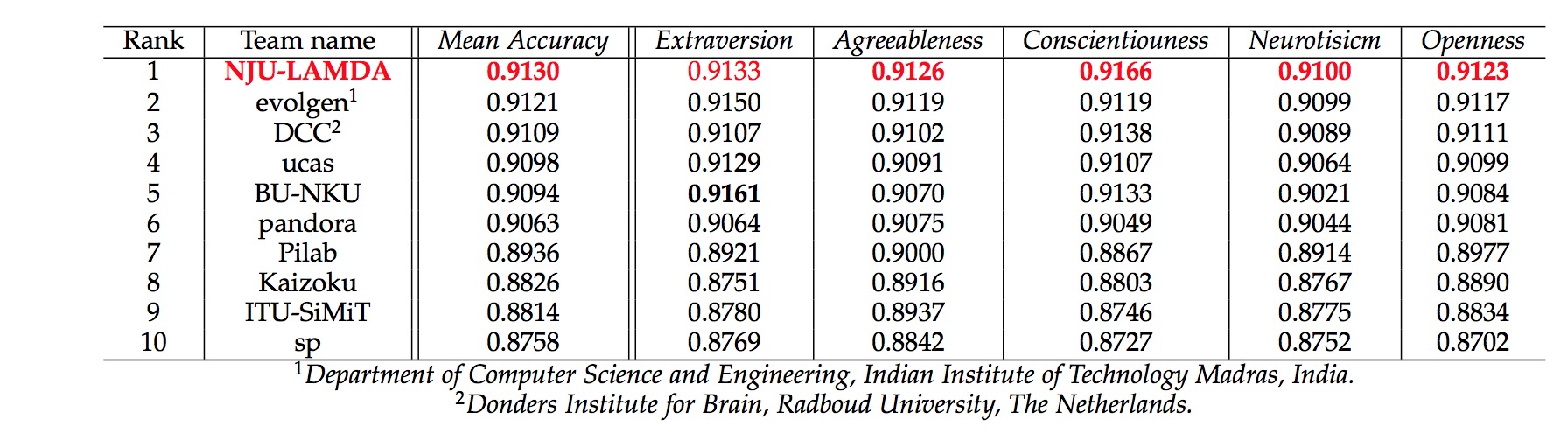 |
In the Final Evaluation phase, we directly employ the optimal models in the Development phase to predict the Big Five traits values on the testing set. The final challenge results are shown in the above table. Our final result (0.9130) ranked the first place, which outperformed the other participants. Moreover, for the regression accuracy of each Big Five trait value, our proposed DBR framework achieved the best result in four traits, i.e., Agreeableness, Conscientiouness, Neurotisicm, and Openness.
Robust Deep Regression Learning
For deep regression of DAN and DAN+, two traditional convex loss functions, i.e., and , are used as the loss to be minimized during the network training. In addition, considering the ground truth label noises, we further deploy the Tukey's biweight function as one kind of non-convex loss function into the visual modality for robust deep regression learning. The advanced experimental results of our IEEE TAC journal paper could validate the effectiveness of the Tukey's biweight loss function on this kind of human-labeled video data. For more details, please refer to our IEEE TAC paper.
Visualization of DANs
DAN Representation Embedding
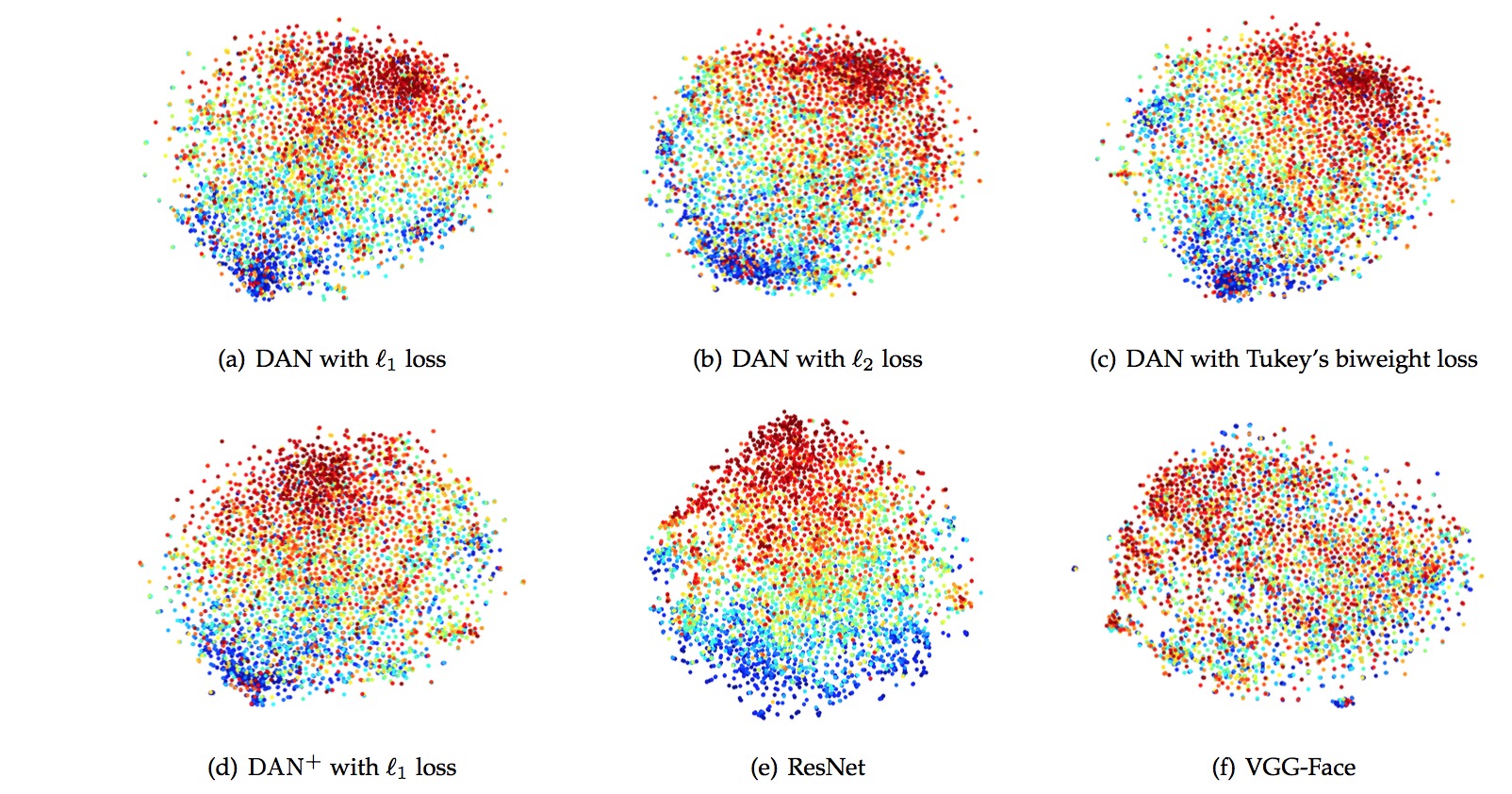 |
These figures show the t-Distributed Stochastic Neighbor Embedding (t-SNE) of the concatenation layer of the models trained on the ChaLearn LAP competition dataset. The feature vectors of different deep networks are preprocessed using PCA to a dimensionality of 50. The perplexity parameters of t-SNE is set to 30. From these figures, it is obvious to find there are two apparent clusters in the visualization of DAN with Tukey's biweight loss. Comparing with that, the blue cluster of DAN with loss and DAN with loss are little mixed and disorderly. For ResNet, it just has an apparent red cluster, and the blue dots are scatted. There is no obvious pattern in the visualization of traditional VGG model.
DAN Activations
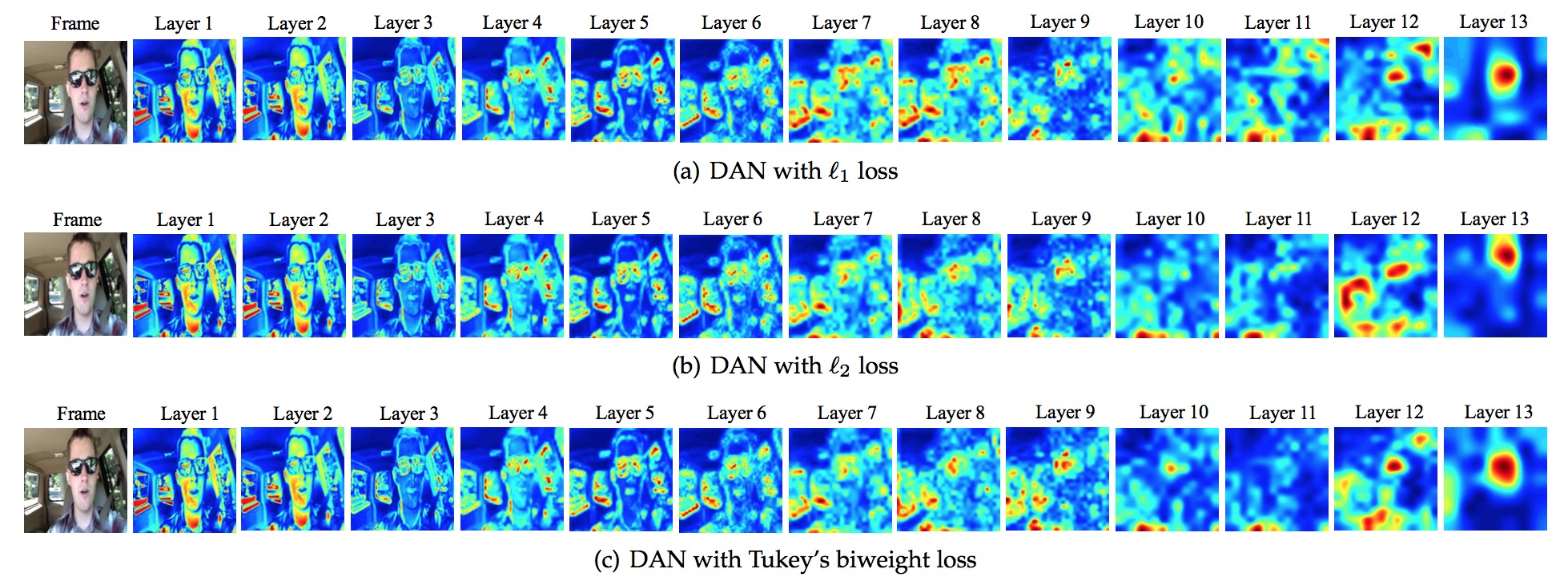 |
In these figures, we present the activations across our DAN models with different loss functions trained on the competition data. The color indicates the maximum activation energy for any feature map for a particular layer. In the first couple of layers, the face of the person and the environment settings can still be recognized, and there is almost no difference between the activation maps of these DAN models. However, with the layer going deeper, the differences emerge, especially for the last three layers.
Related Papers
X.-S. Wei, C.-L. Zhang, H. Zhang, and J. Wu. Deep Bimodal Regression of Personality Traits from Short Video Sequences. IEEE Transactions on Affective Computing (TAC), in press. [code]
C.-L. Zhang, H. Zhang, X.-S. Wei, and J. Wu. Deep Bimodal Regression for Apparent Personality Analysis. In Proceedings of the 14th European Conference on Computer Vision (ECCV’16) Workshops, Amsterdam, The Netherlands, Oct. 2016, LNCS 9915, pp. 311-324. [slide] [code]