Data Ming (Graduate, 2015) Assignments @ NJU-CS
Course: Data Mining (Graduate, 2015)
Teacher: Associate Professor Li-Jun Zhang
Teaching Assistants: Hong Qian and Han-Jia Ye
Grading: Assignments (70%) + Final Examination (30%)
Programming Language: Python / Java / MATLAB
Submission Requirement and Description (Very Important !):
Please use this MSWord template to report your results, and the report must contain your name, student ID, and e-mail address.
Please provide a ReadMe.txt file to describe how to execute your codes.
Please pack your report, code and ReadMe.txt into a zip file named with your student ID, e.g., MG1533001.zip. If you have multiple submissions, add an extra '_' with a number, such as MG1533001_1.zip. We will use the the version with the largest number as your final submission for each assignment.
The file format should be zip, no other format is acceptable.
NO submission after the deadline is acceptable. For example, due on Oct. 10, 2015 means that no submission after 2015-10-10 23:59:59 will be accepted.
NO email submission will be accepted.
Upload your zip file to FTP:
ftp://lamda.nju.edu.cn/mg_dm15/
Please submit your zip file for the first assignment in the Assignment_1 folder, submit your zip file for the second assignment in the Assignment_2 folder, and the like.
username/password of FTP: mg_dm15/mg_dm15
Do NOT plagiarize, plagiarism will be seriously penalized: You should be careful on writing your report. Whenever you are using words and works of others, citations should be made clear such that one can tell which part is actually yours. Details about how to identify a plagiarism can be found in Introduction to the Guidelines for Handling Plagiarism Complaints.
Assignment Evaluation:
We will evaluate your submission according to both implementation (ReadMe.txt file describing how to execute your codes) and report. If plagiarism is identified, no scores will be given to this submission.
For implementation: Efficiency, Performance, Code Style.
For report:
Technique: clearly explain all the component you used in your implementation.
Language: concise, precise, and logical.
Assignment 6 (15%): Real-World Data Mining Competition. (Due on Jan. 10, 2016)
Since we have learned a variety of data mining techniques so far, why not try to participate in a real-world data mining competition now in order to test your ability and see how data mining techniques are applied in the real-world.
In this assignment, you are asked to participate in an ongoing real-world data mining competition held by kaggle (a place where you can compete with world-class data miners on real data mining applications, and at the same time possibly earn a handsome prize). This year, you are asked to design and implement data mining methods to handle the problem: Prudential Life Insurance Assessment (1st place - $15,000). Please participate in the competition alone and teamwork is NOT allowed.
You can click the Prudential Life Insurance Assessment to get all the information you need to accomplish the competition, including how to register, how to get the data, how to evaluate your method. To be explicit, we give a brief guidance for the newcomers of kaggle, which is described below.
Task
Preparations before beginning competition.
Sign up a new account or use an existing Google account to sign in kaggle here.
Find the competition homepage here, where you should read the description, evaluation, rules, prize and all the information you need to know in the left column of the web page.
Accept the licence in this page. Namely, clicking on the “I understand and accept” at the bottom of Make a submission (or My Submissions) web page.
To proceed, you must verify your Kaggle account via your mobile phone. Do not use a public number or share your number with others. Input your phone number (e.g., +8612345678901), then, your phone should receive your verification number. Please enter it and click the “Confirm”.
[Important]: Modify the Team Name (the name which will be shown in the leaderboard) in My Team web page as your student number, e.g., MG1533001. You can use any account name as you like, but the Team Name that will appear in the leaderboard must be your student ID. If your Team Name is not your student ID, your rank will NOT be recorded by us at deadline, and thus your score for rank will be zero.
Participate in the competition and get higher rank as possible as you can.
Log in kaggle with your account and find the competition homepage.
Download the training and test data here.
Use any method you have learned to build a model from training examples, and then use this model to predict the test samples. You can invoke other codes or tools to help you.
Submit the prediction file in Make a submission web page (or My submissions web page) to evaluate your result. The submission format can be found here (sample_submission.csv). You can submit your result multiple times.
If you have submitted one, you will get your rank instantaneously which will be shown in the leaderboard. Try to get higher rank as possible as you can before deadline.
Write a report to describe your methods and implementation.
Submit your report, code, ReadMe, as well as the prediction file to FTP.
What should you submit to FTP
Pack all the files needed to be submitted, i.e., report.docx, code.zip, ReadMe.txt, prediction_on_test.csv. Before submitting your assignment to FTP, please read Submission Requirement and Description section above carefully and obey it.
[Important]: The prediction_on_test.csv should be in the same format as sample_submission.csv given by kaggle. The report should contain your final rank and result before deadline (2016-1-10 23:59:59) in the leaderboard, your name, student ID, and e-mail address. Name this pack using your student ID, e.g., MG1533001.zip.
[Important]: Submission Deadline: 2016-1-10 23:59:59. Please note that the deadline of assignment is before the deadline of competition. You can still go on participating in the competition after Jan. 10, but we only record your rank and result at 2016-1-10 23:59:59 and results after 2016-1-10 23:59:59 will NOT be accepted by us.
How to evaluate the assignment
We will evaluate your submission according to your rank and report. If plagiarism is identified, no scores will be given to this assignment.
For rank:
At 2016-1-10 23:59:59 (please note that the deadline of this assignment is before the deadline of competition), we will get your absolute rank
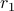 (the rank over all the participants
(the rank over all the participants 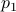 ) and relative rank
) and relative rank 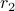 (the rank over all the students from this course
(the rank over all the students from this course 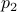 ) from the leaderboard, and then your final score for the rank part is given by:
where
) from the leaderboard, and then your final score for the rank part is given by:
where![mathrm{Score}_{mathrm{rank}} propto frac{1}{2}left(frac{sum_{pin p_1}I[r_p > r_1]}{|p_1|-1} + frac{sum_{pin p_2}I[r_p > r_2]}{|p_2|-1}right),](eqs/1142477731-130.png)
![I[cdot]](eqs/1776449413-130.png) is the indicator function, i.e.,
is the indicator function, i.e., ![I[mathrm{condition}]=1](eqs/157361532-130.png) if condition is true and 0 otherwise.
if condition is true and 0 otherwise.
Please make sure that the name shown in the leaderboard is your student ID. Otherwise, your rank will NOT be recorded by us at deadline, and thus your score for rank will be zero.
For report:
Technique: clearly explain why you choose such method, how you implement the method, and how the method performs on this data mining task.
Language: concise, precise, and logical.
Organization: good structure, clearly and properly separated sections and paragraphs.
Citations: all works of non-yourself should have correct references.
Assignment 5 (15%): Random Forest and AdaBoost. (Due on Dec. 9, 2015)
Please implement two ensemble learning algorithms, which are Random Forest and AdaBoost, for classification tasks. Before implementing them, you should implement a base classifier first.
Dataset
Data: We adopt two binary classification datasets which come from UC Irvine Machine Learning Repository. (Please use editors like Sublime or Notepad++ to open them.)
Data Description and Format: Both of them are binary classification datasets. The first row indicates the type of each feature, i.e., 1 representing discrete feature and 0 representing numeric feature. Except for the first row, each row represents an example. Except for the first row, the last column represents the label of the corresponding example, and the remaining columns represent the features of the corresponding example.
Task Description
Please implement a decision tree algorithm first, and then implement two ensemble learning algorithms which use the decision tree you have implemented as the base classifier. Please implement the algorithms (both decision tree and ensemble algorithms) by yourself, and do not invoke other existing codes or tools. But, for random number generation, you may use the existing codes or tools.
Task 1: Decision Tree for Binary Classification. (Reference: Section 10.3 of the textbook)
Implement only a kind of decision tree algorithm, e.g., ID3 algorithm, C4.5 algorithm, etc.
Handle both discrete and numerical features.
Optional: Use pruning technique to avoid over-fitting. (This step is not necessary for the assignment, but you may gain higher scores if you accomplish this step.)
Task 2: Random Forest for Binary Classification. (Reference: Section 11.8 of the textbook)
Implement the Random Forest algorithm using the decision tree you have implemented in the Task 1 as the base classifier.
Conduct 10 fold cross validation on dataset 1 and 2 for Random Forest, and then report the mean and standard deviation of accuracy.
Task 3: AdaBoost for Binary Classification. (Reference: Section 11.8 of the textbook)
Implement the AdaBoost algorithm using the decision tree you have implemented in the Task 1 as the base classifier.
Conduct 10 fold cross validation on dataset 1 and 2 for AdaBoost, and then report the mean and standard deviation of accuracy.
How to present and evaluate the results:
The report should contain a table that shows the mean and standard deviation of accuracy for Random Forest and AdaBoost on dataset 1 and 2, respectively. Please arrange the table in a proper way. The main part of scores for this assignment will be on the basis of both the performance (accuracy) and the efficiency of the algorithms you have implemented.
Reminders about Submission
The report must contain your name, student ID, and e-mail address.
Submission Deadline: 2015-12-9 23:59:59.
Before submitting your assignment, please read Submission Requirement and Description section above carefully and obey it.
For assignment 5, please pack your report, code and ReadMe.txt into a zip file named with your student ID, e.g., MG1533001.zip.
Assignment 4 (10%): Training Classifiers via SGD. (Due on Nov. 25, 2015)
Please implement two algorithms which are tailored to large-scale classification. Given the datasets with a large number of examples, we will train classifiers via stochastic gradient descent (SGD) in order to make training phase more efficient.
Dataset
Data: We adopt two datasets which come from here. Each dataset contains both training set and testing set. (Please use editors like Sublime or Notepad++ to open them.)
Data Description and Format: Dataset 1 (Training) contains 22696 rows and 124 columns, and dataset 1 (Testing) contains 9865 rows and 124 columns; Dataset 2 (Training) contains 32561 rows and 124 columns, and dataset 2 (Testing) contains 16281 rows and 124 columns. Each row represents an example. The last column represents the label of the corresponding example, and the remaining columns represent the features of the corresponding example. For each dataset, label
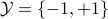 .
.
Task Description
Please first download the article, and then accomplish the following two tasks which are depicted in the article. Please implement the algorithms by yourself, and do not invoke other existing codes or tools. But, for basic vector or matrix operations and random number generation, you may use the existing codes or tools.
Task 1: Binary classification with the hinge-loss on dataset 1 and 2.
Training phase (on the training set): Please implement the Pegasos algorithm which is depicted in the Section 2.1 Figure 1 of the article (page 4-5) you have downloaded.
Please note that the bias term here is ignored, i.e.,
 .
.For simplicity, please ignore line 10 in the Figure 1 of the article when implementing the Pegasos algorithm.
Let
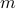 denote the number of examples in the training set, set
denote the number of examples in the training set, set 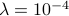 for training dataset 1 and
for training dataset 1 and 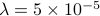 for training dataset 2, and set
for training dataset 2, and set 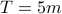 .
.
Testing phase (on the testing set): Please test the classifier you have trained and record the test error in the testing set, i.e., comparing the label that the classifier predicts with the true label and recording the error rate.
Task 2: Binary classification with the log-loss on dataset 1 and 2.
Training phase (on the training set): Replace the hinge-loss with log-loss, and keep the others as same as the the Pegasos algorithm mentioned in the Task 1. The definition of log-loss and its sub-gradient can be found in the Section 5 (Example 1 and the table therein) of the article.
Testing phase (on the testing set): As same as the Task 1.
How to present the results of Task 1 and 2:
The report should contain four figures and a table that show the test error with respect to the number of iterations 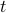 for each loss function on each dataset. Specifically,
for each loss function on each dataset. Specifically,
for the four figures: x-axis of the figure is the number of iterations
in the training phase, and y-axis is the test error ranging from 0 to 1. For each dataset and each loss function (four figures in total), please plot the test error when 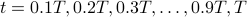 (where and is the number of examples in the training set) with 10 points, and connect these 10 points with lines.
(where and is the number of examples in the training set) with 10 points, and connect these 10 points with lines.for the table: arrange the value of test error with respect to
for each loss function on each dataset depicted above in a table.
Reminders about Submission
The report must contain your name, student ID, and e-mail address.
Submission Deadline: 2015-11-25 23:59:59.
Before submitting your assignment, please read Submission Requirement and Description section above carefully and obey it.
For assignment 4, please pack your report, code and ReadMe.txt into a zip file named with your student ID, e.g., MG1533001.zip.
Assignment 3 (15%): Clustering. (Due on Nov. 8, 2015)
Please implement three clustering algorithms: k-means, clustering by non-negative matrix factorization (NMF), and spectral clustering.
Dataset
Data: The two datasets come from Statlog/German and the MNIST database of handwritten digits, respectively. Some modifications are made by us from the original datasets, e.g., normalization. (Please use editors like Sublime or Notepad++ to open them. )
Data Description and Format: Dataset 1 contains 1000 rows and 25 columns, and dataset 2 contains 10000 rows and 785 columns. Each row represents an example. The last column represents the label of the corresponding example, and the remaining columns represent the features of the corresponding example. Namely, dataset 1 contains 1000 examples, and each example has 24 features and 1 label; dataset 2 contains 10000 examples, and each example has 784 features and 1 label. The number of classes in dataset 1 is 2, and the number of classes in dataset 2 is 10.
Task Description
Please download the task description PDF file and implement three clustering algorithms described in it. Some requirements and suggestions are listed below:
Please simply set the number of clusters for each dataset as the number of classes, i.e., the number of clusters for dataset 1 is 2 and the number of clusters for dataset 2 is 10.
The label information in each dataset is used to calculate the Purity and Gini index only.
Please implement three algorithms by yourself, and do not invoke other existing codes or tools. But, for computing generalized eigenvalue, generalized eigenvector, and matrix inverse, you may use the existing codes or tools.
You may download the two papers below which are mentioned in the task description PDF file:
The report should contain pseudo-codes of three algorithms and the final results. The final results presented in the report should be organized as shown in the task description PDF file.
Reminders about Submission
The report must contain your name, student ID, and e-mail address.
Submission Deadline: 2015-11-8 23:59:59.
Before submitting your assignment, please read Submission Requirement and Description section above carefully and obey it.
For assignment 3, please pack your report, code and ReadMe.txt into a zip file named with your student ID, e.g., MG1533001.zip.
Assignment 2 (10%): Frequent Itemset Mining. (Due on Oct. 25, 2015)
Frequent itemsets can be applied to generate association rules. For the given dataset, we will implement the Apriori algorithm to accomplish the frequent itemset mining task.
Dataset
Data: Data Download (Please use editors like Sublime or Notepad++ to open it. )
Data Description and Format: The dataset contains 1001 rows and 11 columns. Each column represents an item and there are 11 items. The first row represents the name of each item and they are 1,2,...,10,11. Row 2 to row 1001 represent all the transactions, and each row among them represents a transaction. In row 2 to row 1001, for each transaction, 1 represents that the corresponding item appears in this transaction and 0 represents that the corresponding item does not appear in this transaction. For example, the second row in the dataset (0 1 1 0 0 0 0 0 0 0 1) means that only items 2,3,11 appear in the first transaction.
Task Description
Please read Section 4.4.2 of the textbook carefully, and implement the Apriori algorithm in Section 4.4.2. The three main steps of the Apriori algorithm are candidate generation, pruning, and support counting. For the support counting step in the Apriori algorithm, please implement the efficient support counting method in Section 4.4.2.1. Please implement the Apriori algorithm by yourself, and do NOT invoke other existing codes or tools.
Parameters of the Apriori algorithm:
Transactions: the dataset we provide. (Please use the name of items as we provide.)
Minimum Support: minsup = 0.144
The report should contain pseudo-codes of the three main steps of the Apriori algorithm:
candidate generation: non-repetitive and exhaustive way of generating candidates;
pruning: the level-wise pruning trick;
support counting (as Section 4.4.2.1): counting the number of occurrences of each candidate in the transaction dataset.
Please generate a result.txt file which contains the frequent itemsets you have mined and the corresponding support values. In order for us to evaluate your result efficiently, please organize your result as follows: each line represents a frequent itemset and its support value (the last number in each line). Please arrange the frequent itemsets in lexicographically sorted order, and use only three decimals to show the support values. Separate the numbers in each line with space. Result below is an illustration of the format of result.txt. Please note that it is not the correct answer and only for illustration.
2 0.410
2 6 0.321
2 6 10 0.157
2 10 0.303
6 0.405
6 10 0.310
10 0.421
11 0.417
Reminders about Submission
Submission Deadline: 2015-10-25 23:59:59.
Before submitting your assignment, please read Submission Requirement and Description section above carefully and obey it.
For assignment 2, please pack your report, code, ReadMe.txt and result.txt into a zip file named with your student ID, e.g., MG1533001.zip.
Assignment 1 (5%): Chinese Text Data Processing. (Due on Oct. 10, 2015)
Some problems have been found in the submitted assignments to FTP. Thus, we provide a note (note download) to point out these problems and give some suggestions on your submissions. Please read the note and refine your submission in order to gain higher scores.
Dataset
Data: Data Download (Data Source: Forum Classification based on the posts from the Lily BBS)
Data Description and Format: The zip file contains 10 txt files (10 classes). Each txt file contains more than 100 lines, and each line represents a raw post. You may regard each line in each txt file as an instance/example of the corresponding class.
Task Description
First, please do the tokenization job to get the words from the Chinese sentences. You may use some existing tools like jieba for python, or IKAnalyzer for java, to help you accomplish the tokenization job.
Second, please delete the stop words. We provide a Chinese stop words list for your reference, and you can download it.
Third, please extract TF-IDF (Term Frequency–Inverse Document Frequency) features from the raw text data on the basis of step 1 and step 2 above. You may learn or review TF-IDF here. Please implement extracting TF-IDF features by yourself, and do NOT invoke other existing codes or tools.
Four, please generate 10 new txt files which only contain TF-IDF features for each class, each line in each new txt file represents the TF-IDF feature of an instance/example in the corresponding class. Please name the 10 new txt files as same as the original 10 txt files that we provide.
We provide a detailed task description to depict what we should do in Assignment 1 for your reference. You may download here.
Reminders about Submission
Submission Deadline: 2015-10-10 23:59:59.
Before submitting your assignment, please read Submission Requirement and Description section above carefully and obey it.
For assignment 1, in addition to submit your report, code and ReadMe.txt, you need to submit a folder named result. The result folder contains the 10 new txt files as described in step 4 above. Please pack your report, code, ReadMe.txt and result into a zip file named with your student ID, e.g., MG1533001.zip.