Sheng-Hua Wan @ LAMDA, NJU-AI
 |
万盛华 |
|


Short Biography
I received my B.Sc. degree of GIS from Nanjing University, in June 2021. In the same year, I was admitted to study for a Ph.D. degree in Nanjing University without entrance examination in the LAMDA Group led by professor Zhi-Hua Zhou, under the supervision of Prof. De-Chuan Zhan.
Research Interests
My research interest includes Reinforcement Learning and its real-world applications, and mainly focus on sim2real problems:
Policy-induced World Model Learning
Learning World Models under Cross-Modality Observations
Learning Control in Noisy Environments
Fundings
Learning World Models under Cross-Modality Observations. The Young Scientists Fund of the National Natural Science Foundation of China (PhD Candidate) (624B200197) 2025.01-2026.12
Policy Transfer via Cross-modality Imitation under the Sim2Real Gap. Postgraduate Research & Practice Innovation Program of Jiangsu Province (KYCX24_0302) 2024.05-2025.05
Characteristics and mechanism of global flood teleconnection Frontier Science Center for Critical Earth Material Cycling - "GeoX" Project (2024300270) 2024.01-2024.12
Publications - Conference
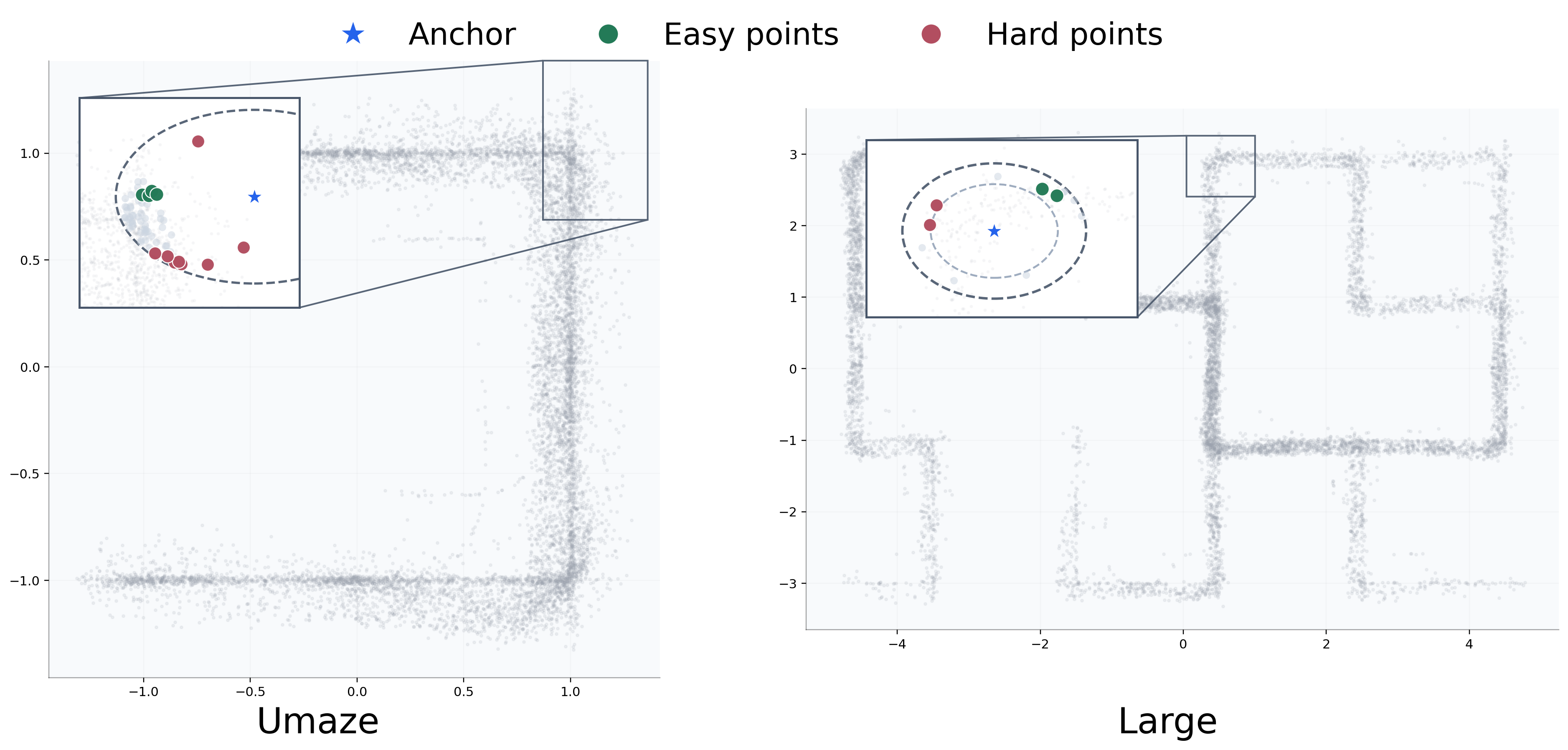 |
We investigates the role of the isolation kernel and its distribution extensions in reachability modeling for offline Markov decision process sequences, and constructs a unified analytical framework that combines state-level and distribution-level approaches. At the state level, the isolation kernel is used to characterize offline state similarity and is applied to state retrieval, offline k-nearest neighbor relabeling, and offline k-nearest neighbor planning; at the distribution level, an isolated distribution kernel is used to measure the similarity of the set of successor states after H steps. |
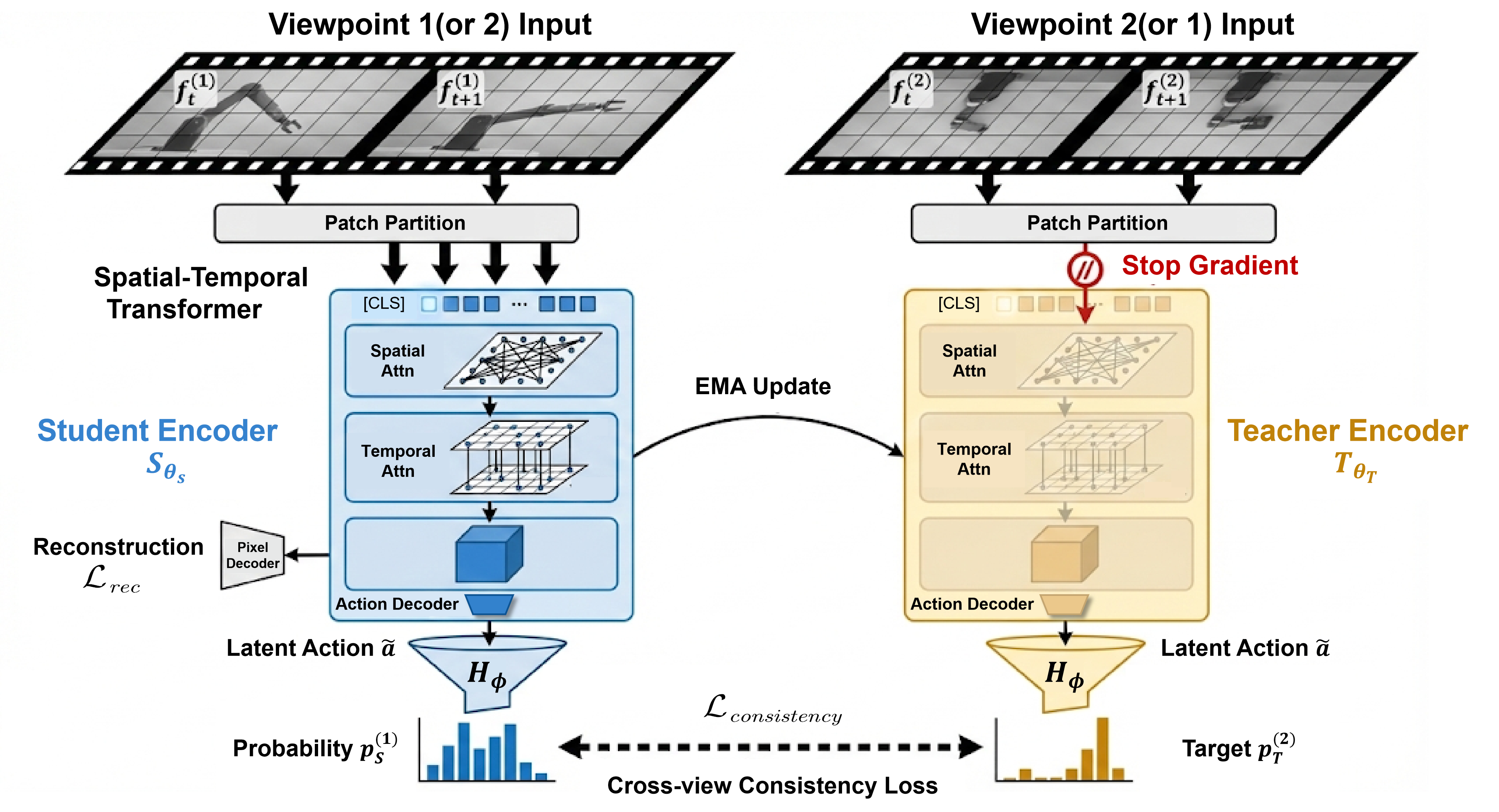 |
We introduce MuCoLA (Multi-view Consistent Latent Action learning), a framework that learns robust, view-invariant action representations by enforcing semantic consistency across synchronized video streams. Departing from restrictive Gaussian priors, MuCoLA utilizes a Student-Teacher network with DINO-style self-distillation to align action representations across views, effectively filtering high-frequency visual noise while preserving motion semantics. Theoretical analysis reveals that our multi-view objective functions as a spectral filter, isolating agent dynamics from environmental nuisances. |
 |
Prevailing methods train models to predict a single, deterministic future, an objective that is ill-posed for inherently stochastic environments where actions are unknown. We contend that a world model should instead learn a structured, probabilistic representation of the future where predictive uncertainty correctly scales with the temporal horizon. To achieve this, we introduce a pre-training framework, Horizon-cAlibrated Uncertainty World Model (HAUWM), built on a probabilistic ensemble that predicts frames at randomly sampled future horizons. |
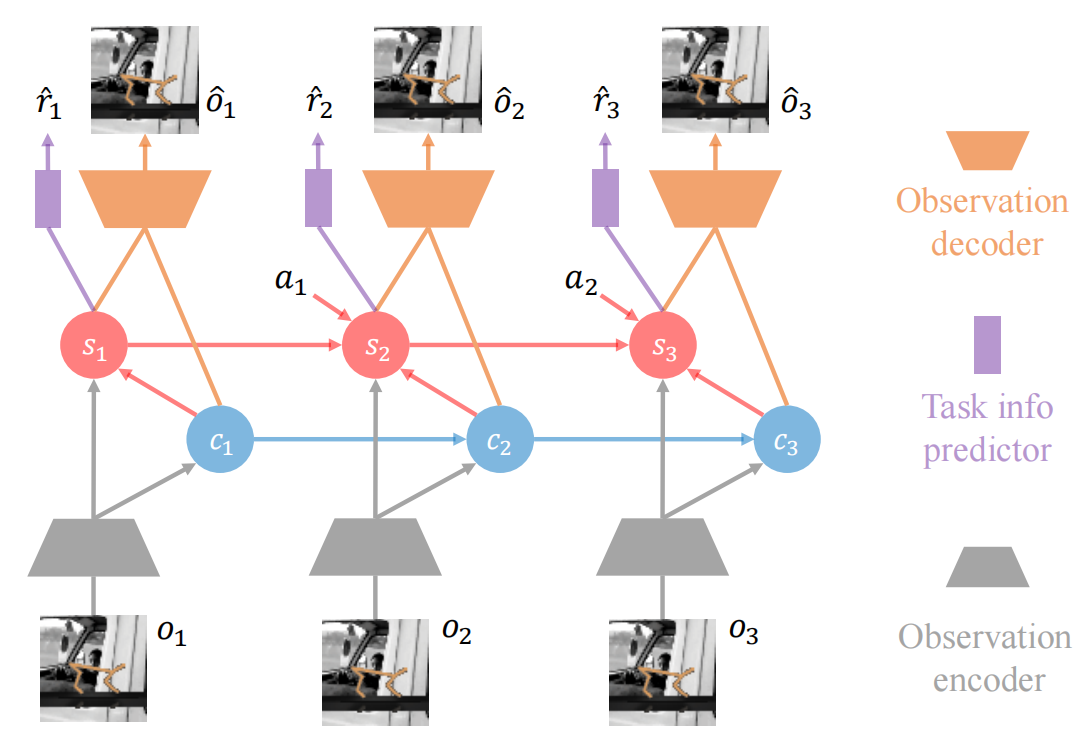 |
We introduce CsDreamer, a model-based RL approach built upon the world model of Collider-Structure Recurrent State-Space Model (CsRSSM). CsRSSM incorporates colliders to comprehensively model the denoising inference process and explicitly capture the conditional dependence. Furthermore, it employs a decoupling regularization to balance the influence of this conditional dependence. By accurately inferring a task-relevant state space, CsDreamer improves learning efficiency during rollouts. |
 |
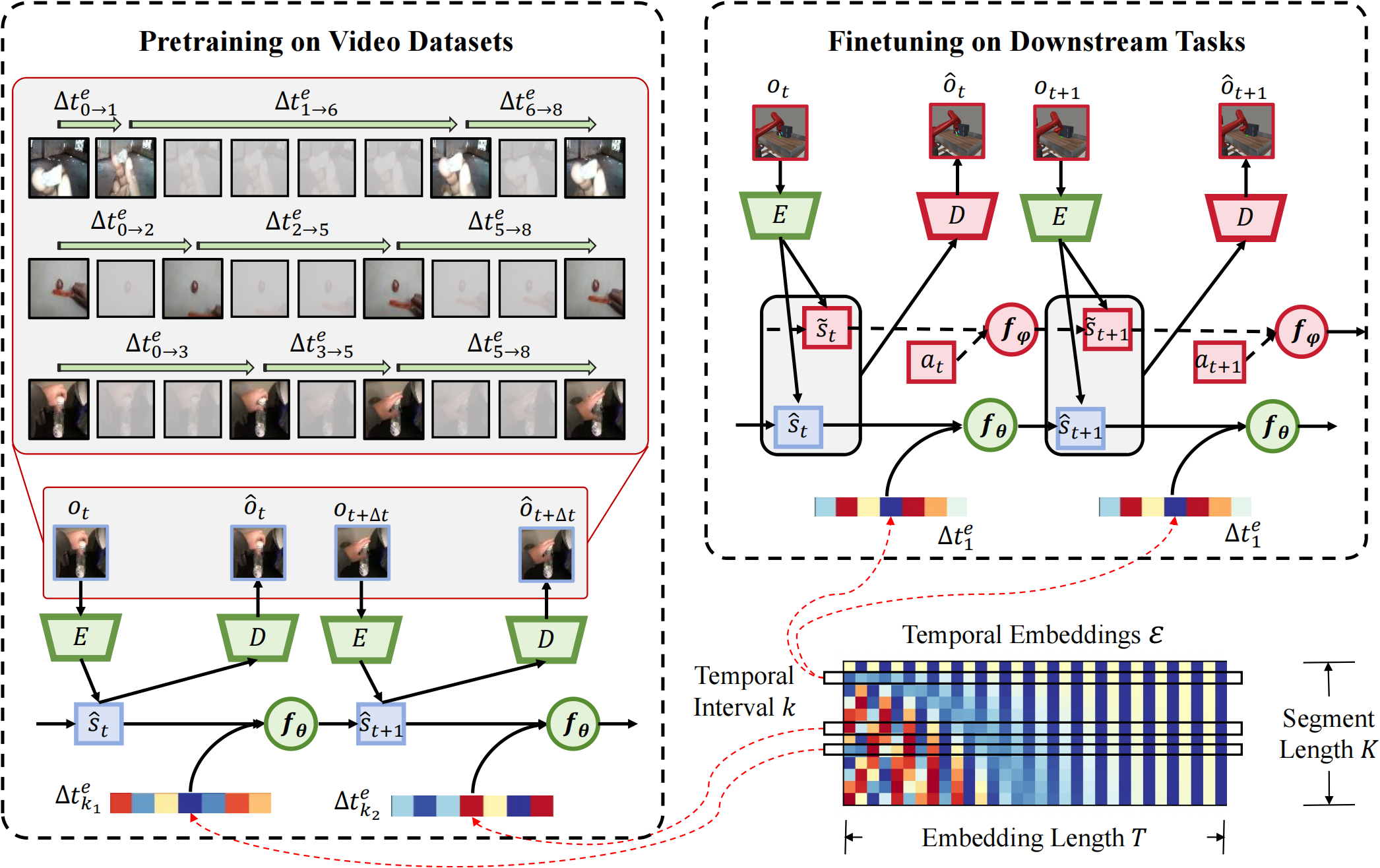
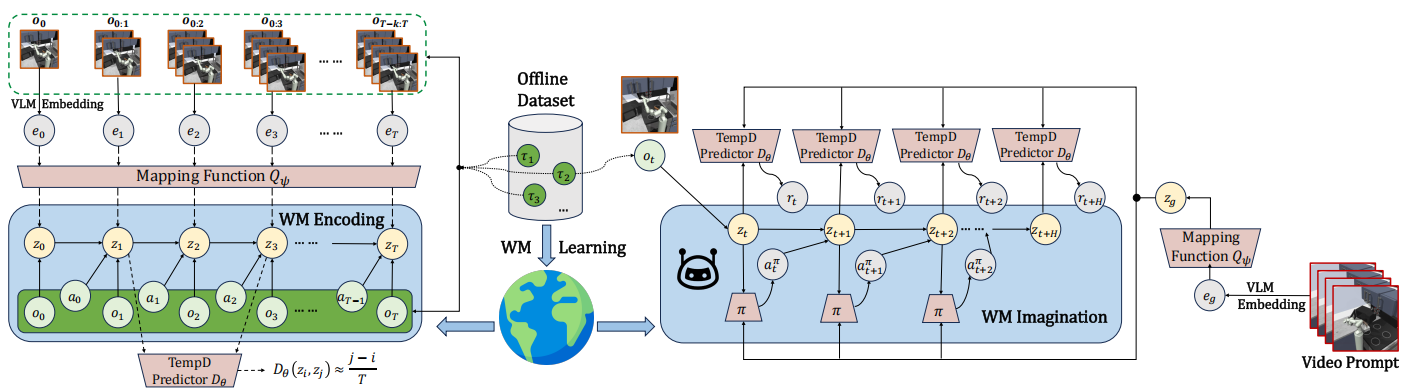
Pre-training world models enhances sample efficiency in reinforcement learning, but existing methods struggle with capturing causal mechanisms due to the absence of explicit action labels in video data. We propose MAPO (Multimodal-large-model-generated Action-based pre-training from videOs), which introduces a novel framework that utilizes visual-language models to generate detailed semantic action descriptions, establishing action-state associations with causal explanations. Experimental results demonstrate that MAPO significantly improves performance on the DeepMind Control Suite and Meta-World, particularly in long-horizon tasks, underscoring the importance of semantic action generation for causal reasoning in world model training. |
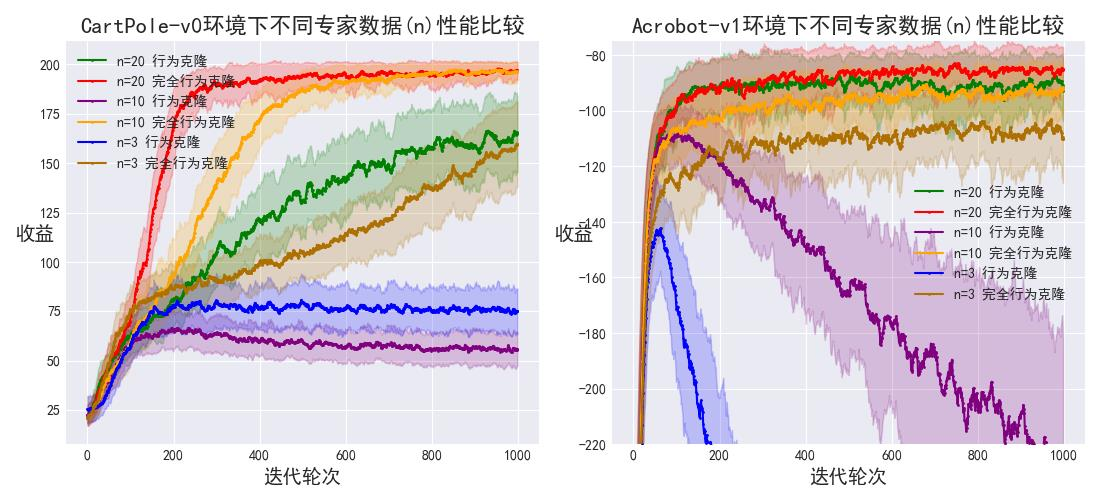 |
In the imitation learning method of Behavior Cloning (BC), agents often take random actions when facing states not covered by expert data, leading to compounding errors that hinder performance. This paper presents Complete Behavior Cloning (CBC), an enhanced version of BC that aligns more comprehensively with expert knowledge while addressing these errors. Our experiments show that CBC reduces compounding errors, improves transferability, enhances robustness to noise, and decreases reliance on expert data, highlighting the effectiveness of twice learning in reinforcement learning. |
 |
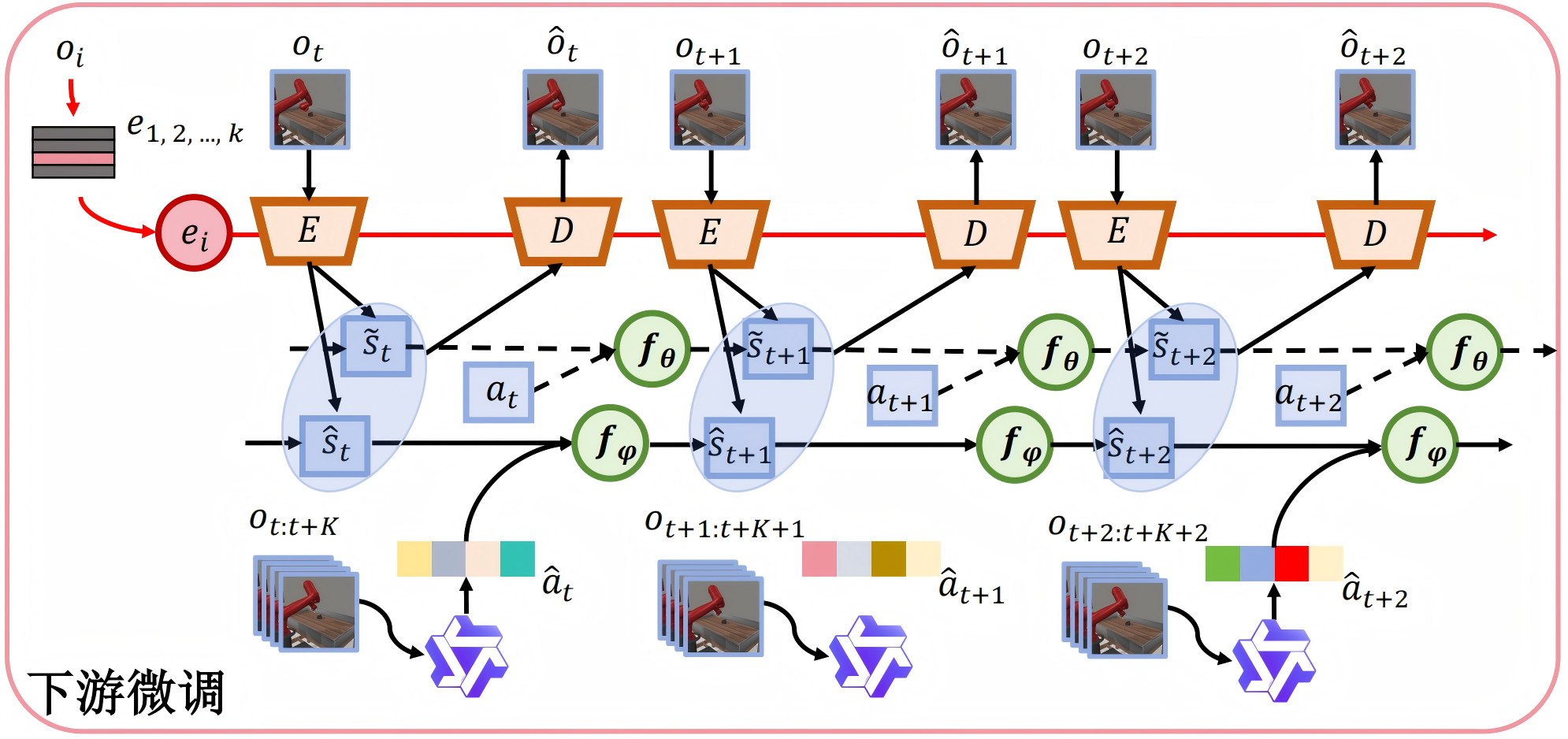
we propose FOUNDER, a framework that integrates the generalizable knowledge embedded in FMs with the dynamic modeling capabilities of WMs to enable open-ended decision-making in embodied environments in a reward-free manner. We learn a mapping function that grounds FM representations in the WM state space, effectively inferring the agent's physical states in the world simulator from external observations. |
 |
In this survey, we provide a comprehensive review of reward modeling techniques within the RL literature. We begin by outlining the background and preliminaries in reward modeling. Next, we present an overview of recent reward modeling approaches, categorizing them based on the source, the mechanism, and the reward learning paradigm. Building on this understanding, we discuss various applications of these reward modeling techniques and review methods for evaluating reward models. Finally, we conclude by highlighting promising research directions in reward modeling. Altogether, this survey includes both established and emerging methods, filling the vacancy of a systematic review of reward models in current literature. |
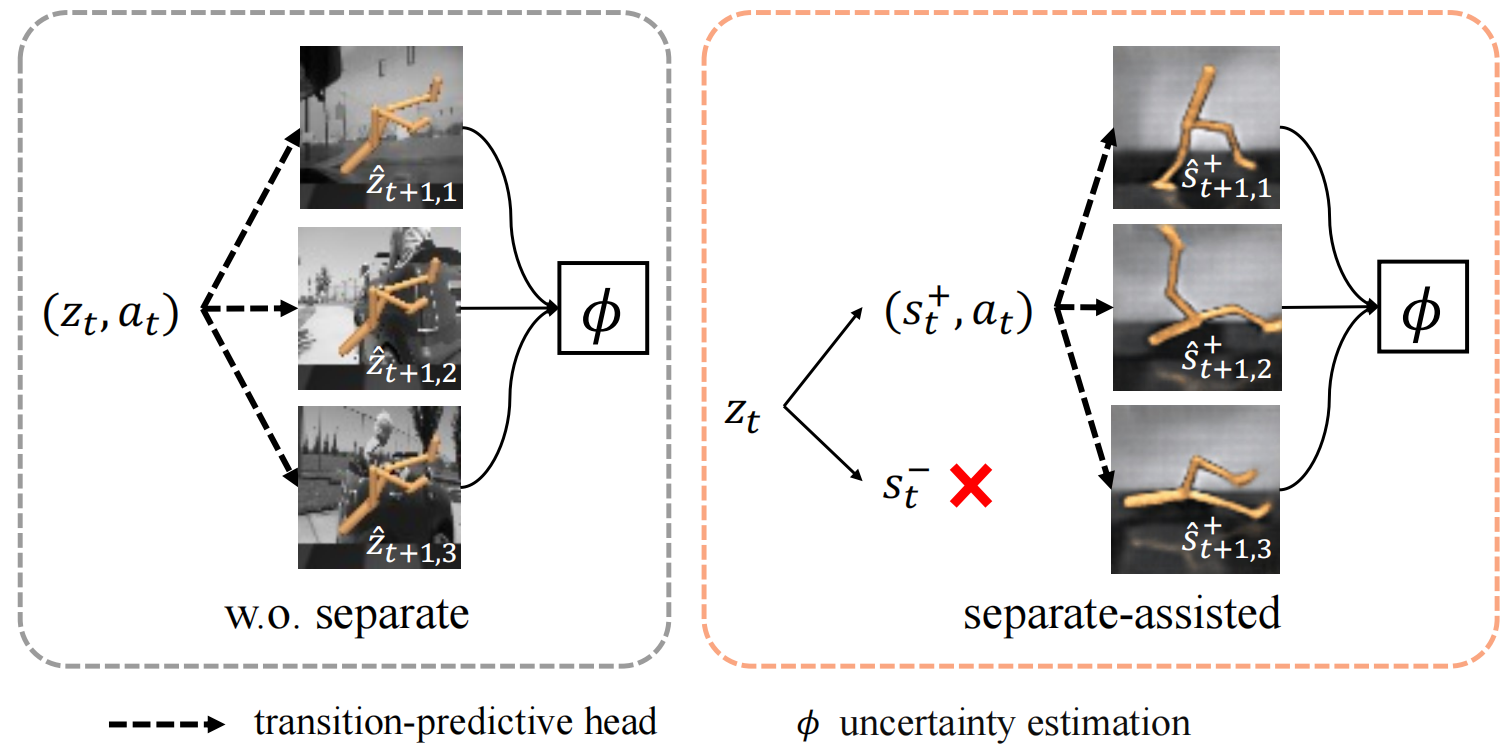 |
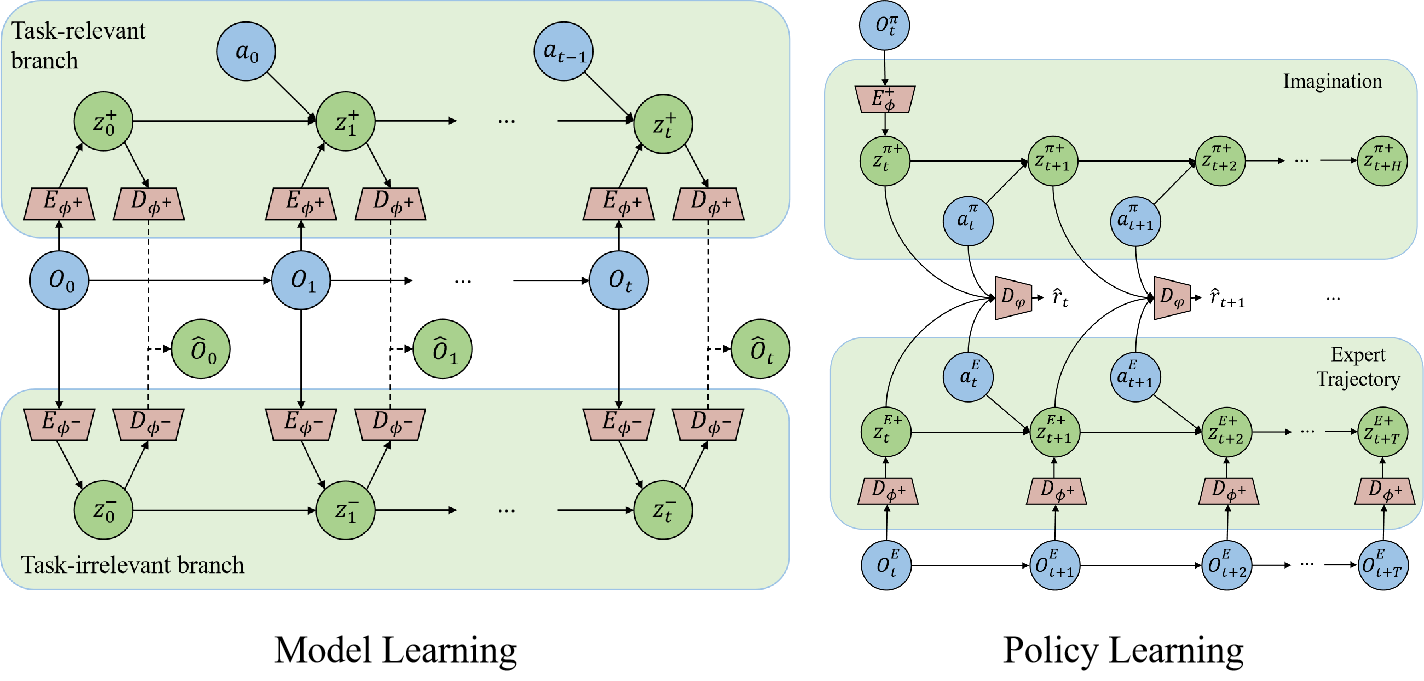
We propose a bi-level optimization framework named Separation-assisted eXplorer (SeeX). In the inner optimization, SeeX trains a separated world model to extract exogenous and endogenous information, minimizing uncertainty to ensure task relevance. In the outer optimization, it learns a policy on imaginary trajectories generated within the endogenous state space to maximize task-relevant uncertainty. |
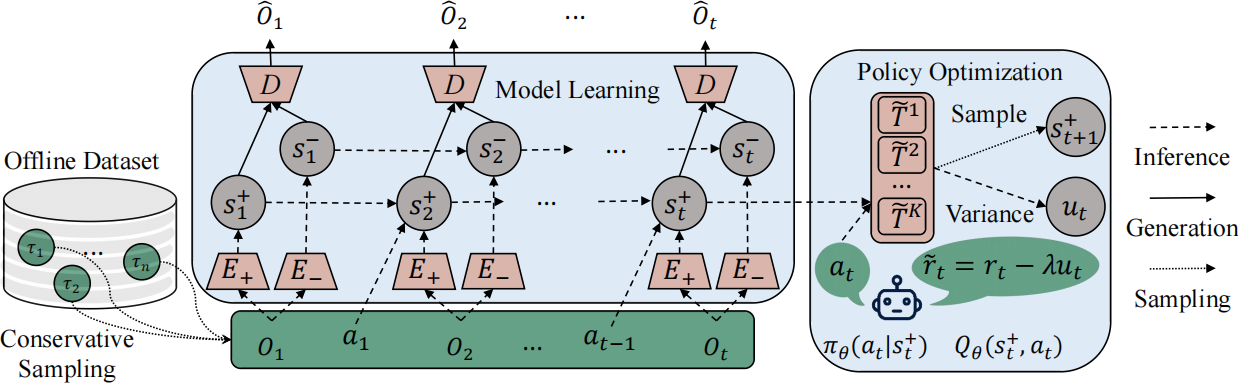 |
We propose a new approach - Separated Model-based Offline Policy Optimization (SeMOPO) - decomposing states into endogenous and exogenous parts via conservative sampling and estimating model uncertainty on the endogenous states only. We provide a theoretical guarantee of model uncertainty and performance bound of SeMOPO, and construct the Low-Quality Vision Deep Data-Driven Datasets for RL (LQV-D4RL). |
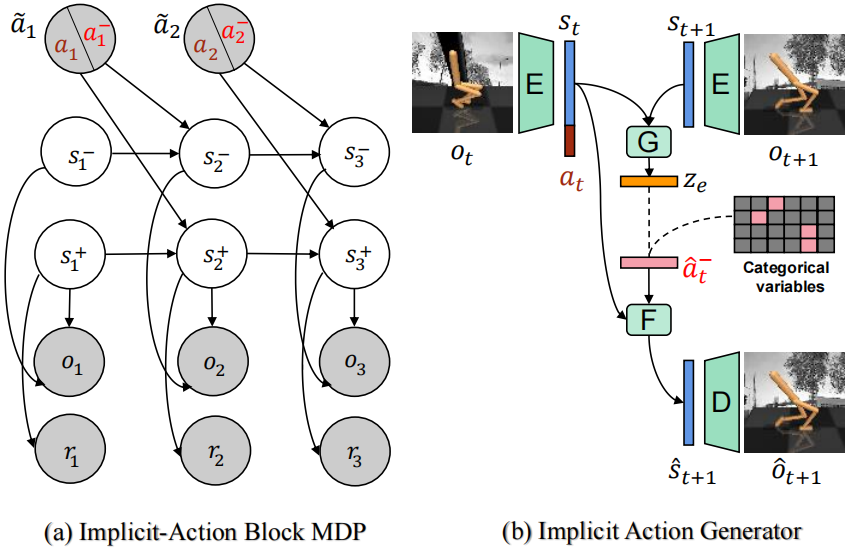 |
We propose Implicit Action Generator (IAG) to learn the implicit actions of visual distractors, and present a new algorithm named implicit Action-informed Diverse visual Distractors Distinguisher (AD3), that leverages the action inferred by IAG to train separated world models. |
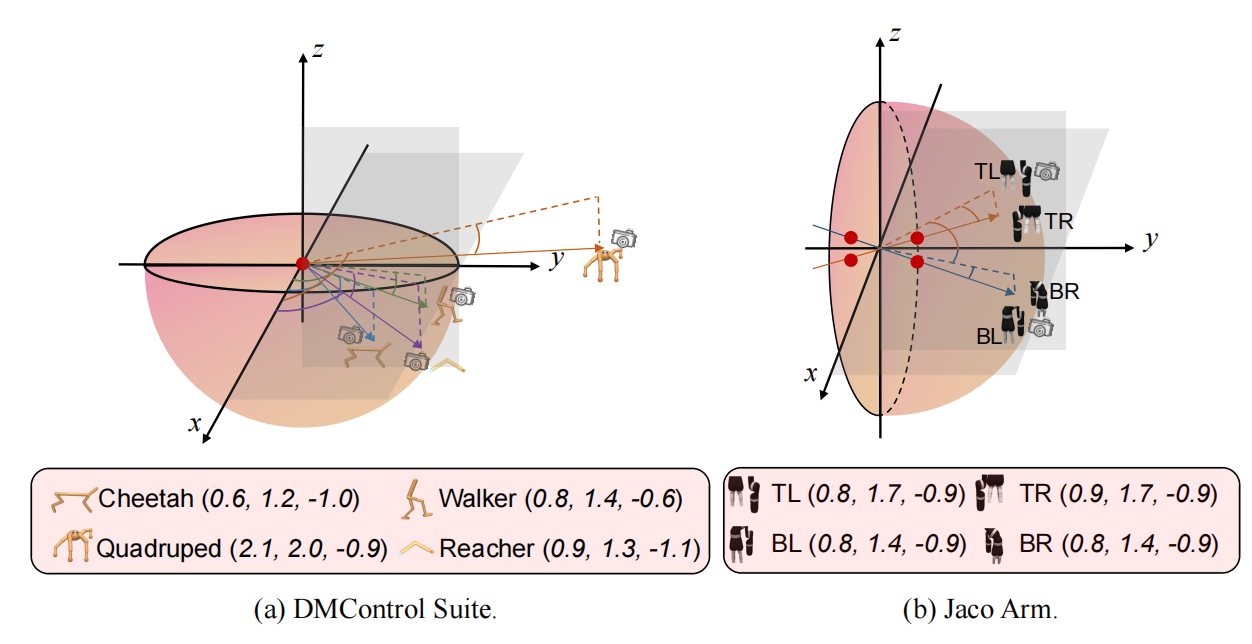 |
We propose the View-conditional Markov Decision Process (VMDP) assumption and develop a new method, the MOdel-based SEnsor controlleR (MOSER), based on VMDP. MOSER jointly learns a view-conditional world model (VWM) to simulate the environment, a sensory policy to control the camera, and a motor policy to complete tasks. |
 |
We propose a new algorithm - named Separated Model-based Adversarial Imitation Learning (SeMAIL) - decoupling the environment dynamics into two parts by task-relevant dependency, which is determined by agent actions, and training separately. |
Publications - Journal
|
|
Pre-training world models enhances sample efficiency in reinforcement learning, but existing methods struggle with capturing causal mechanisms due to the absence of explicit action labels in video data. We propose MAPO (Multimodal-large-model-generated Action-based pre-training from videOs), which introduces a novel framework that utilizes visual-language models to generate detailed semantic action descriptions, establishing action-state associations with causal explanations. Experimental results demonstrate that MAPO significantly improves performance on the DeepMind Control Suite and Meta-World, particularly in long-horizon tasks, underscoring the importance of semantic action generation for causal reasoning in world model training. |
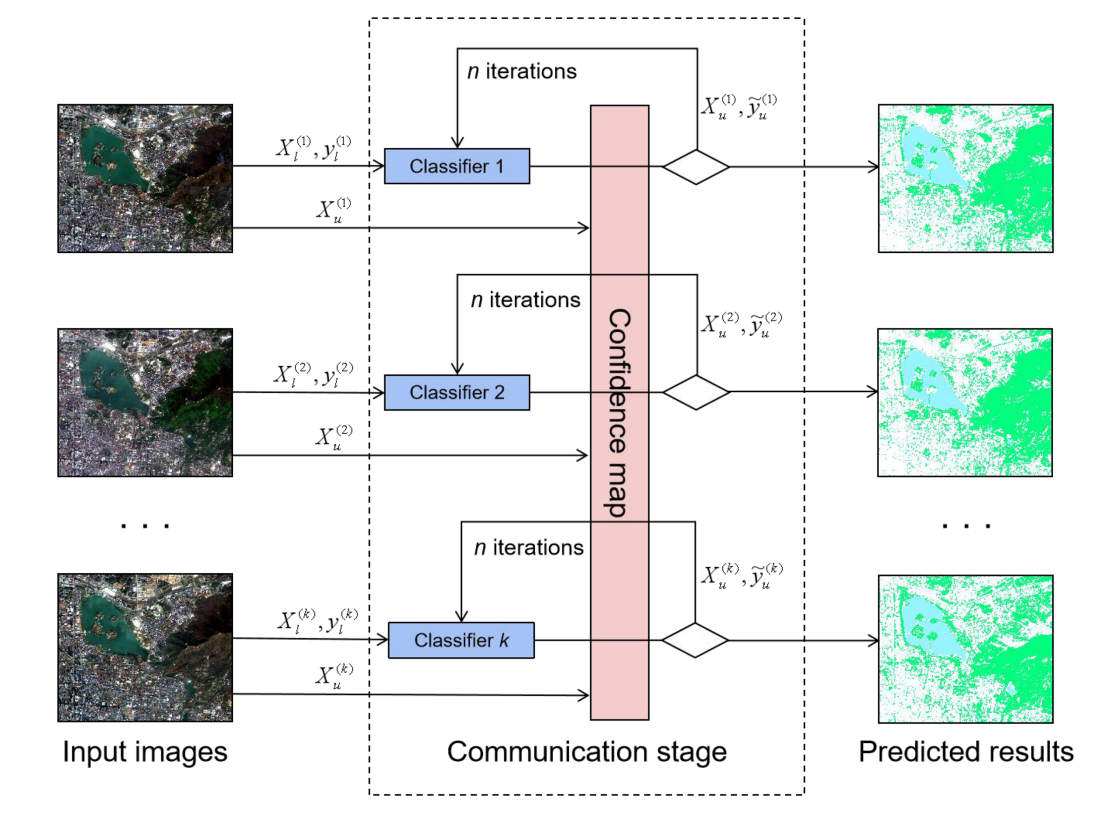 |
We designed a general multitemporal framework to extract urban green cover using multi-training, a novel semi-supervised learning method for land cover classification on multitemporal remote sensing images. |
Preprints
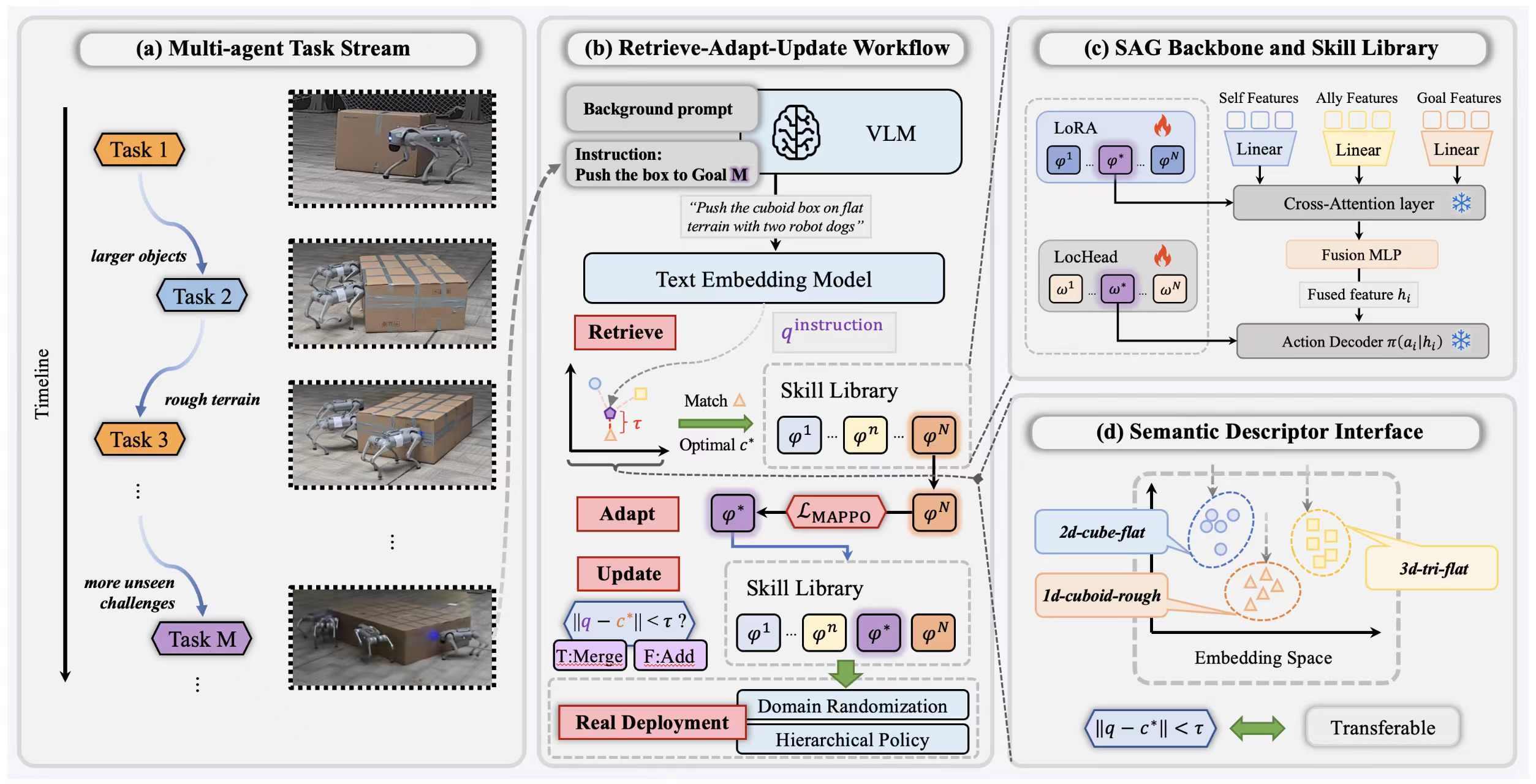 |
We propose Conquer, a semantic skill-library framework that models continual multi-quadruped coordination as a skill retrieve-adapt-update process. For each incoming task, Conquer first builds a semantic descriptor from pre-execution information and retrieves a relevant skill from the library; it then either reuses the retrieved policy or adapts a new skill adapter through MAPPO, and finally updates or expands the library using descriptors extracted from successful trajectories. This process is built on a team-structured Self-Allies-Goal (SAG) backbone that supports variable-size robot teams while keeping stored skills parameter-isolated. |
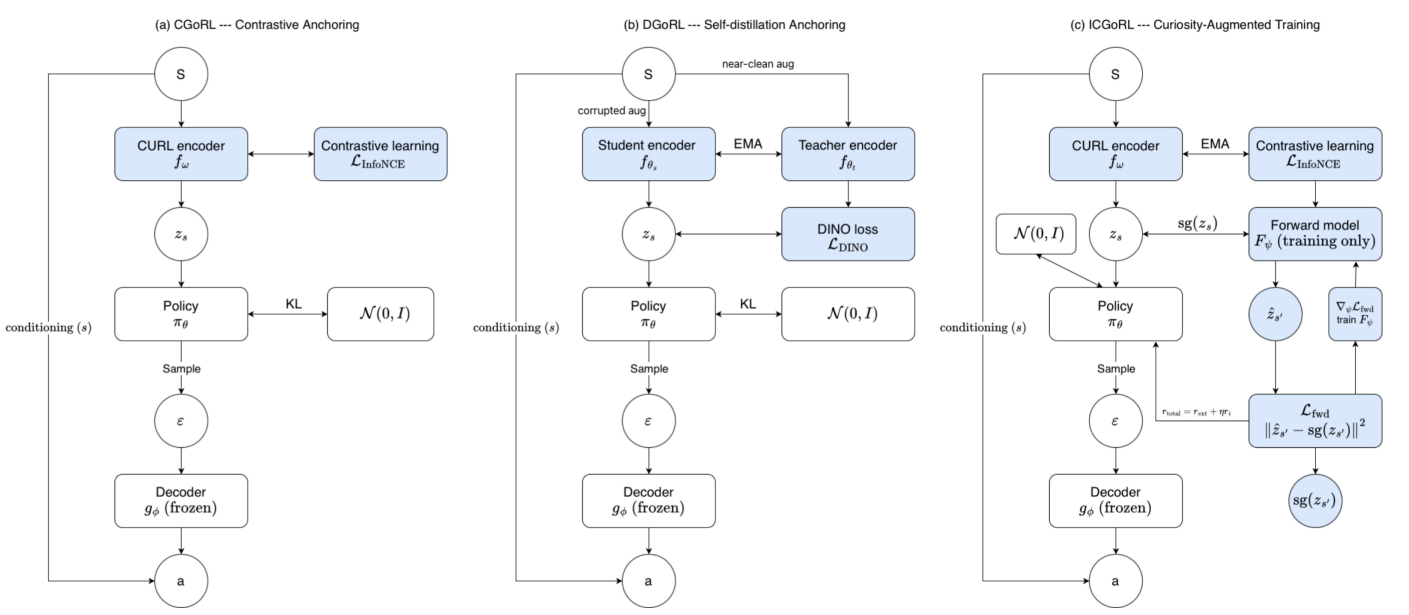 |
We investigate generative online RL by proposing and testing three methods targeting representation drift, policy collapse, and exploration deficiency. Experiments across diverse tasks reveal that no single method universally improves performance, as their effectiveness is highly task-dependent. The study concludes that the challenges cannot be pinned on a single cause and advocates for future designs to be guided by fine-grained, task-conditioned diagnostics. |
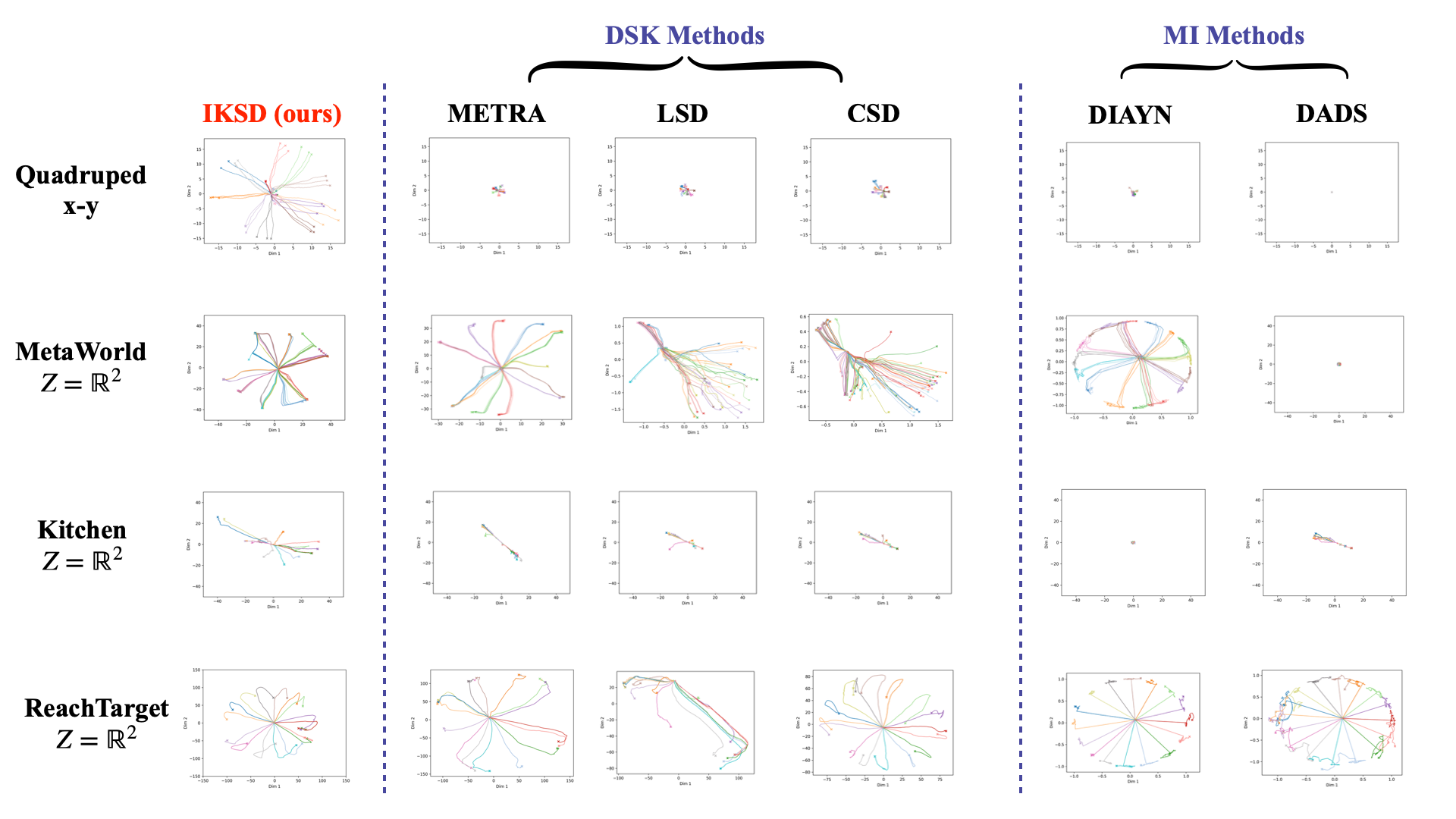 |
Unsupervised Skill Discovery aims to learn a distinguishable, controllable, and broadly-covered skill pool via intra-skill consistency and inter-skill diversity. However, existing skill measures like temporal distance or mutual information ignore the local geometry and density structure of the state space. To this end, we propose Isolation Kernel-aware Skill Discovery (IKSD), introducing an Isolation Kernel in the hidden space to construct data-adaptive similarity and geometric scales to better distinguish cross-skill dynamics and improve learning stability. In addition, we propose skill evaluation metrics to measure skill cohesion and inter-skill separation, and estimating the coverage of state space without relying on downstream tasks. |
 |
We propose Building Reusability via Interface Composition Kinetics for Structured World Models (BRICKS-WM), a framework for the modular assembly of structured world models. We hypothesize that global dynamics can be decomposed into distinct subsystems interacting via shared protocols. As a minimal instantiation of this framework, we factorize the latent state space into an actuated Agent module and an external Background module, bridged by a learned latent interface. Distinct from prior object-centric methods that prioritize visual segmentation, BRICKS-WM enforces a functional separation in transition dynamics, ensuring that background physics remains agnostic to the agent's embodiment. |
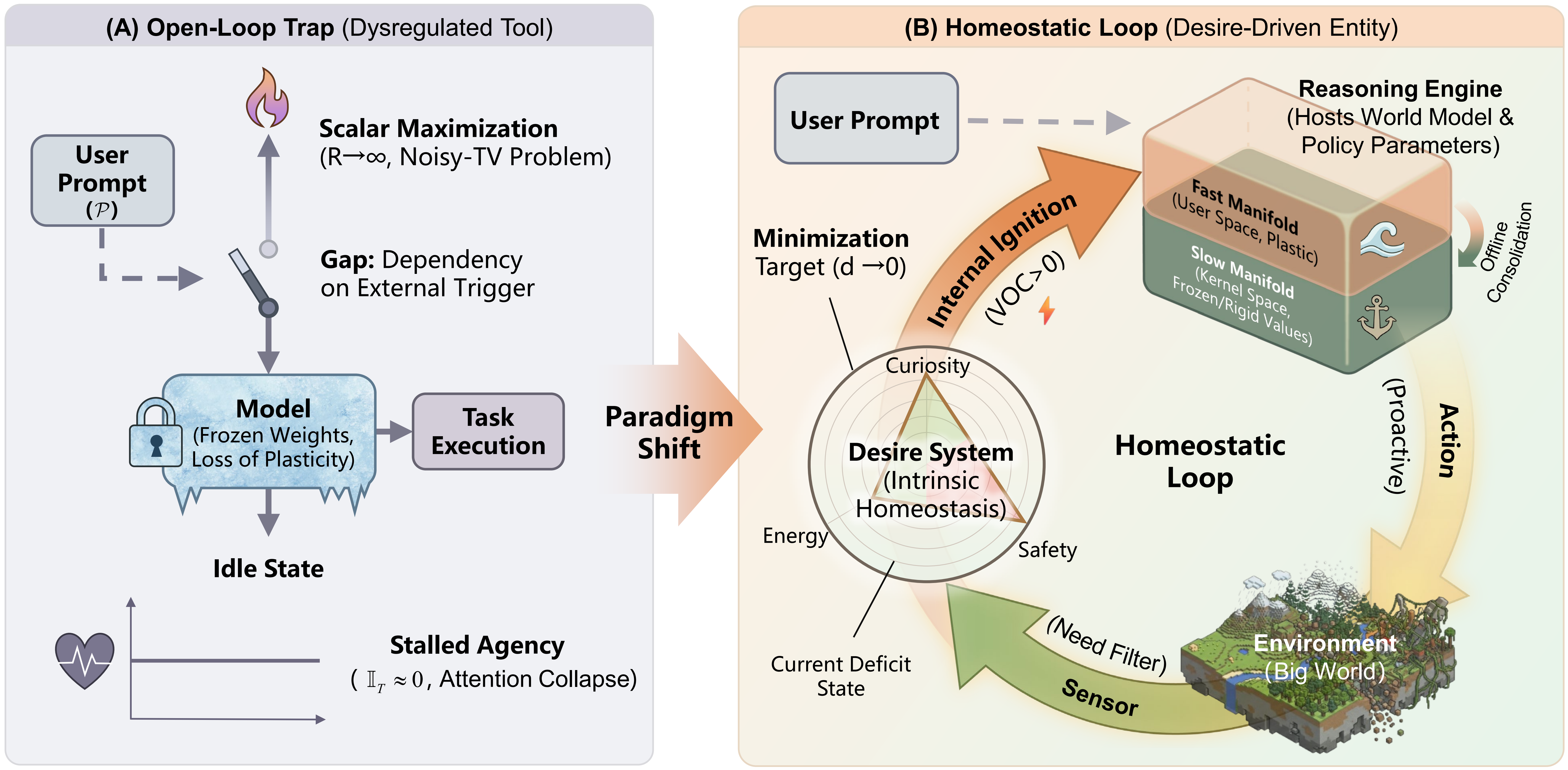 |
Rather than maximizing scalar rewards for specific tasks, agents must be driven by multi-dimensional, internal homeostatic needs that necessitate the continuous tracking of environmental variables. We propose that this teleological shift requires a corresponding structural evolution in memory architecture: moving from frozen weights to a stratified, plastic substrate. This framework transforms AI from reactive instruments into desire-driven entities capable of maintaining coherence and purpose without human intervention. |
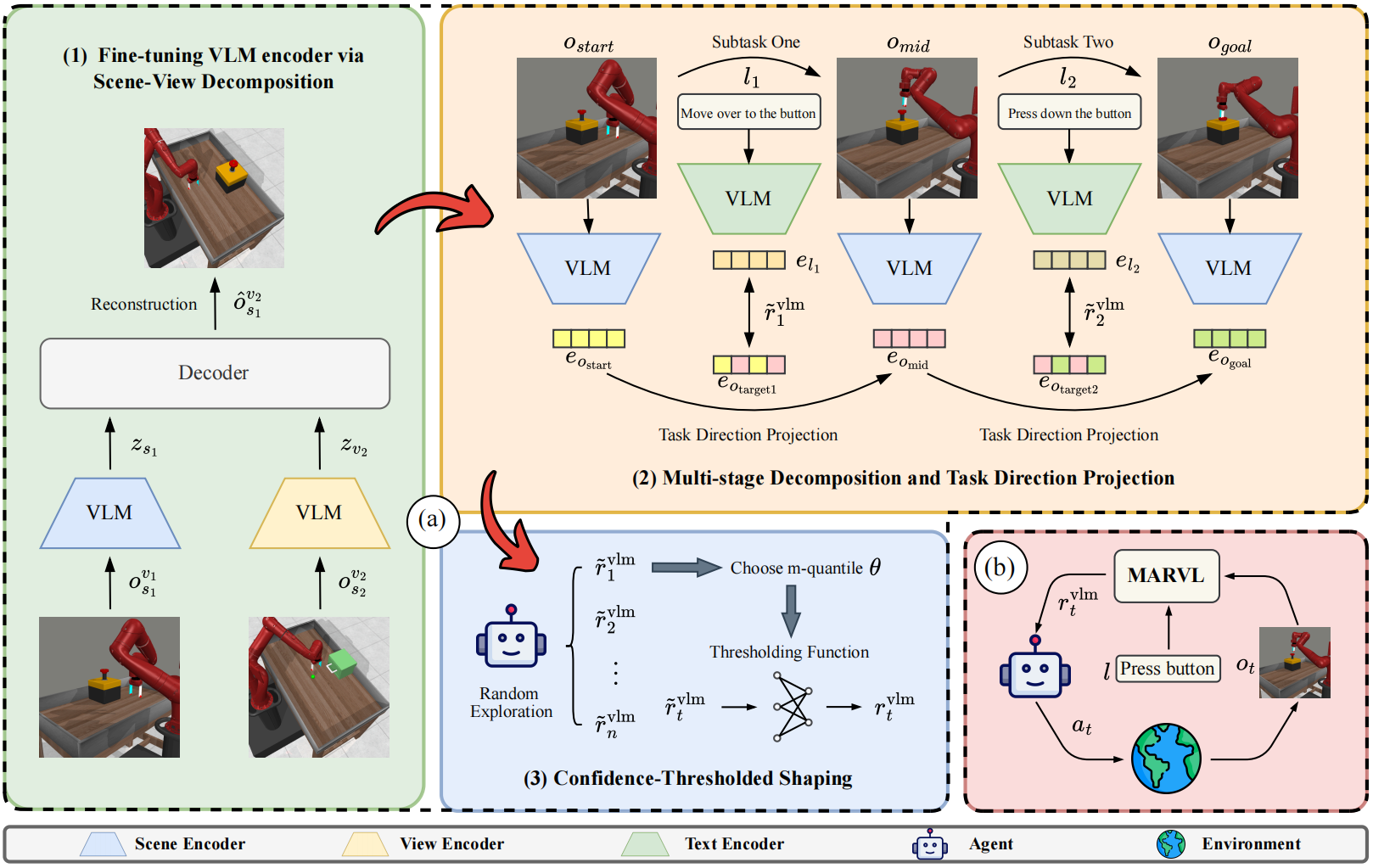 |
While Vision–Language Models (VLMs) offer a promising path to reward design, naive VLM rewards often misalign with task progress, struggle with spatial grounding, and show limited understanding of task semantics. To address these issues, we propose MARVL—Multi-stage guidance for Robotic manipulation via Vision Language models. MARVL fine-tunes a VLM for spatial and semantic consistency and decomposes tasks into multi-stage subtasks with task direction projection for trajectory sensitivity. |
 |
Unsupervised Reinforcement Learning (URL) allows agents to develop general behaviors and representations without relying on external rewards. This survey provides a clear overview of the field, organizing recent advances through a unified framework along four axes: learning paradigm, optimization objective, data regime, and agent quantity. We discuss important challenges, such as long-term exploration, transferring skills from simulation to real-world settings, and open-ended learning, while outlining a path for future research on developing autonomous agents. |
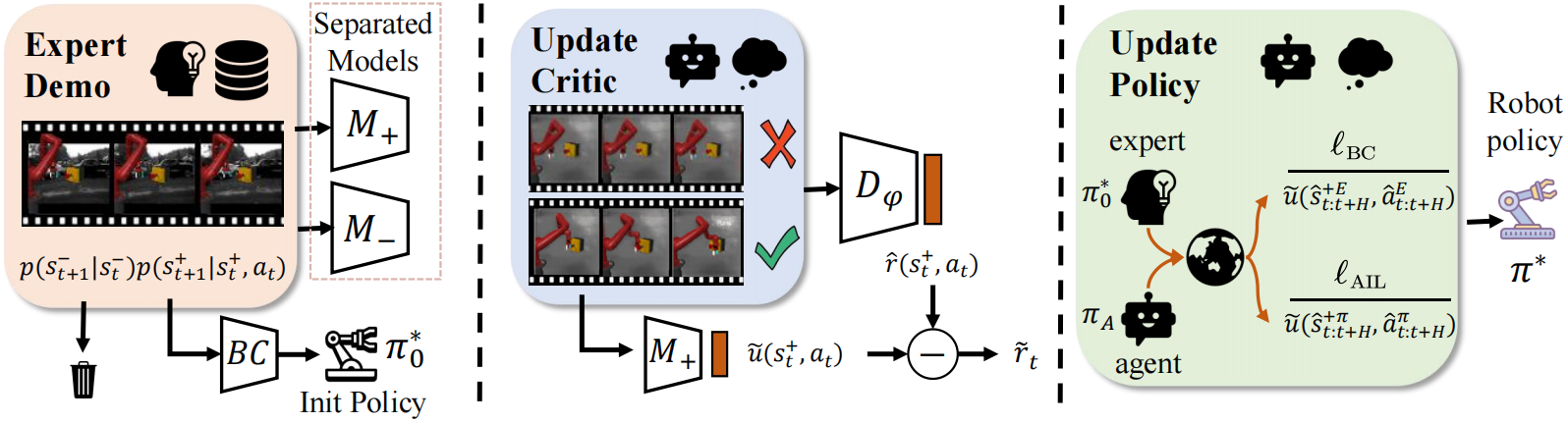 |
We propose eFfective model-based Imitation in visually Noisy Environments (FINE), which incorporates expert demonstration-guided exogenous uncertainty reduction, endogenous model uncertainty-penalized reward estimation, and uncertainty-aware policy learning. We theoretically analyze the benefits of FINE’s design and derive a tight performance bound for imitation. Empirical results on visual imitation tasks validate both the superior performance of our method and its effectiveness in uncertainty reduction. |
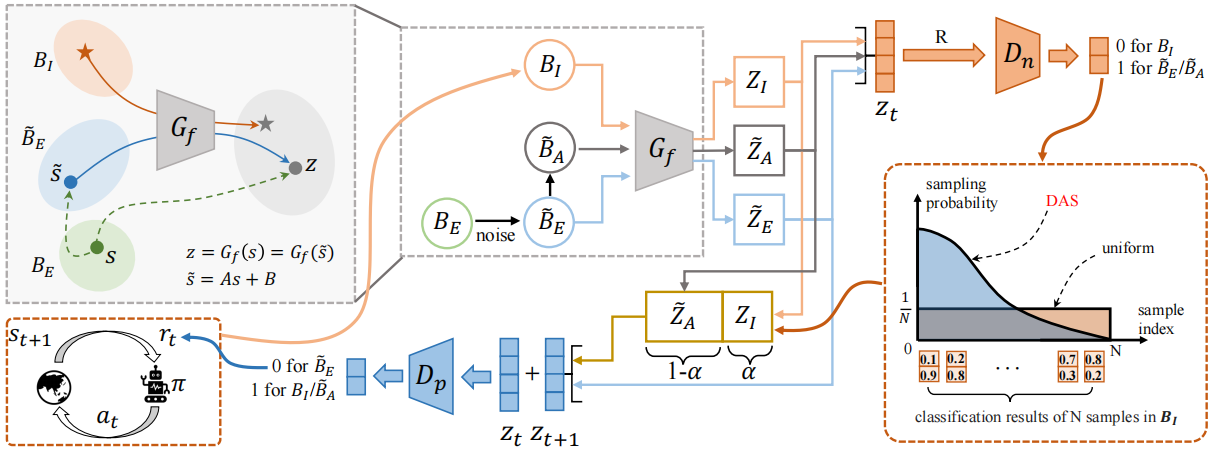 |
We focus on the problem of Learning from Noisy Demonstrations (LND), where the imitator is required to learn from data with noise that often occurs during the processes of data collection or transmission. We propose Denoised Imitation learning based on Domain Adaptation (DIDA), which designs two discriminators to distinguish the noise level and expertise level of data, facilitating a feature encoder to learn task-related but domain-agnostic representations. |
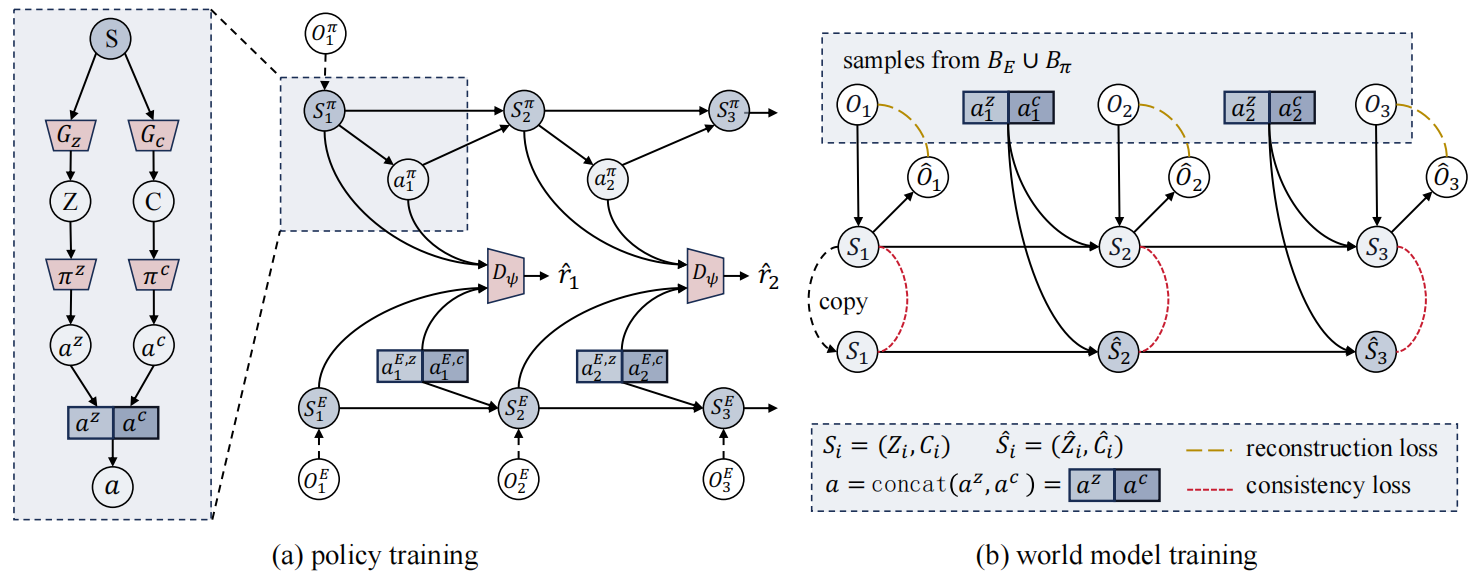 |
We introduce active sensoring in the visual IL setting and propose a model-based SENSory imitatOR (SENSOR) to automatically change the agent's perspective to match the expert's. SENSOR jointly learns a world model to capture the dynamics of latent states, a sensor policy to control the camera, and a motor policy to control the agent. |
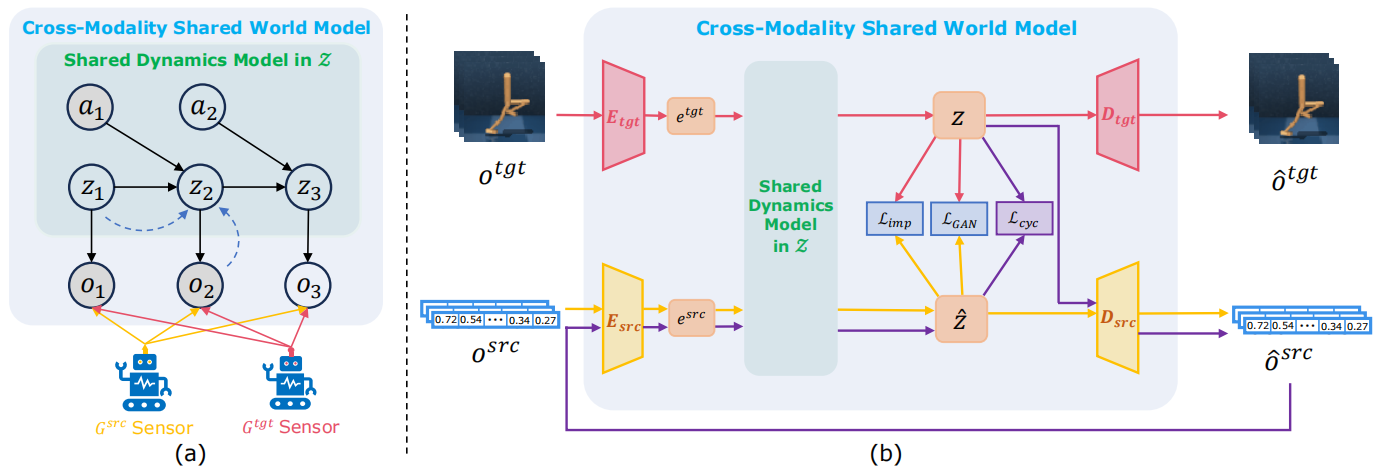 |
We propose CROss-MOdality Shared world model (CROMOS), a co-modality framework that trains an environmental dynamics model in the latent space by simultaneously aligning the source and target modality data to it for the subsequent policy training. We conduct a theoretical proof of the data utilization effectiveness and provide a practical implementation for our framework. |
Selected Honors
MStar intern at Momenta, 2025.06-09
LAMDA Outstanding Contribution Award, 2024.12
National Scholarship for Doctoral Students, 2024.12
LAMDA Excellent Student Award, 2024.05
Ruli scholarship, 2023.11
Winner of the Ping An Insurance Data Mining Competition, 2021.12
Presidential Special Scholarship for first year Ph.D. Student in Nanjing University, 2021.09
Outstanding Graduate of Nanjing University, 2021.06
2-nd place in ZhongAn Cup Insurance Data Mining Competition, 2020.10
Academic Services
Reviewer of NeurIPS (2023, 2024, 2025), ICML (2024, 2025, 2026), ICLR (2026), AAAI (2026), PR, TNNLS, TETCI, CJE
Introduction to Machine Learning. (For undergraduate students, Spring, 2022, Teaching assistant)
Correspondence
Email:
wansh [at] lamda.nju.edu.cn
Office:
Yifu Building, Xianlin Campus of Nanjing University
Address:
National Key Laboratory for Novel Software Technology, Nanjing University, Xianlin Campus Mailbox 603, 163 Xianlin Avenue, Qixia District, Nanjing 210023, China
(南京市栖霞区仙林大道163号, 南京大学仙林校区603信箱, 软件新技术国家重点实验室, 210023.)