Scalable Multiple Instance Learning
 |
Authors
Abstract
Multi-instance learning (MIL) has been widely applied to diverse applications involving complicated data objects such as images and genes. However, most existing MIL algorithms can only handle small- or moderate-sized data. In order to deal with large scale MIL problems, we propose miVLAD and miFV, two efficient and scalable MIL algorithms. They map the original MIL bags into new vector representations using their correspond- ing mapping functions. The new feature representations keep essential bag-level information, and at the same time lead to excellent MIL performances even when linear classifiers are used. Thanks to the low computational cost in the mapping step and the scalability of linear classifiers, miVLAD and miFV can handle large scale MIL data efficiently and effectively. Experiments show that miVLAD and miFV not only achieve comparable accuracy rates with state-of-the-art MIL algorithms, but also have hundreds of times faster speed. Moreover, we can regard the new miVLAD and miFV representations as multi-view data, which improves the accuracy rates in most cases. In addition, our algorithms perform well even when they are used without parameter tuning (i.e., adopting the default parameters), which is convenient for practical MIL applications.
Highlights
Accuracy Comparison
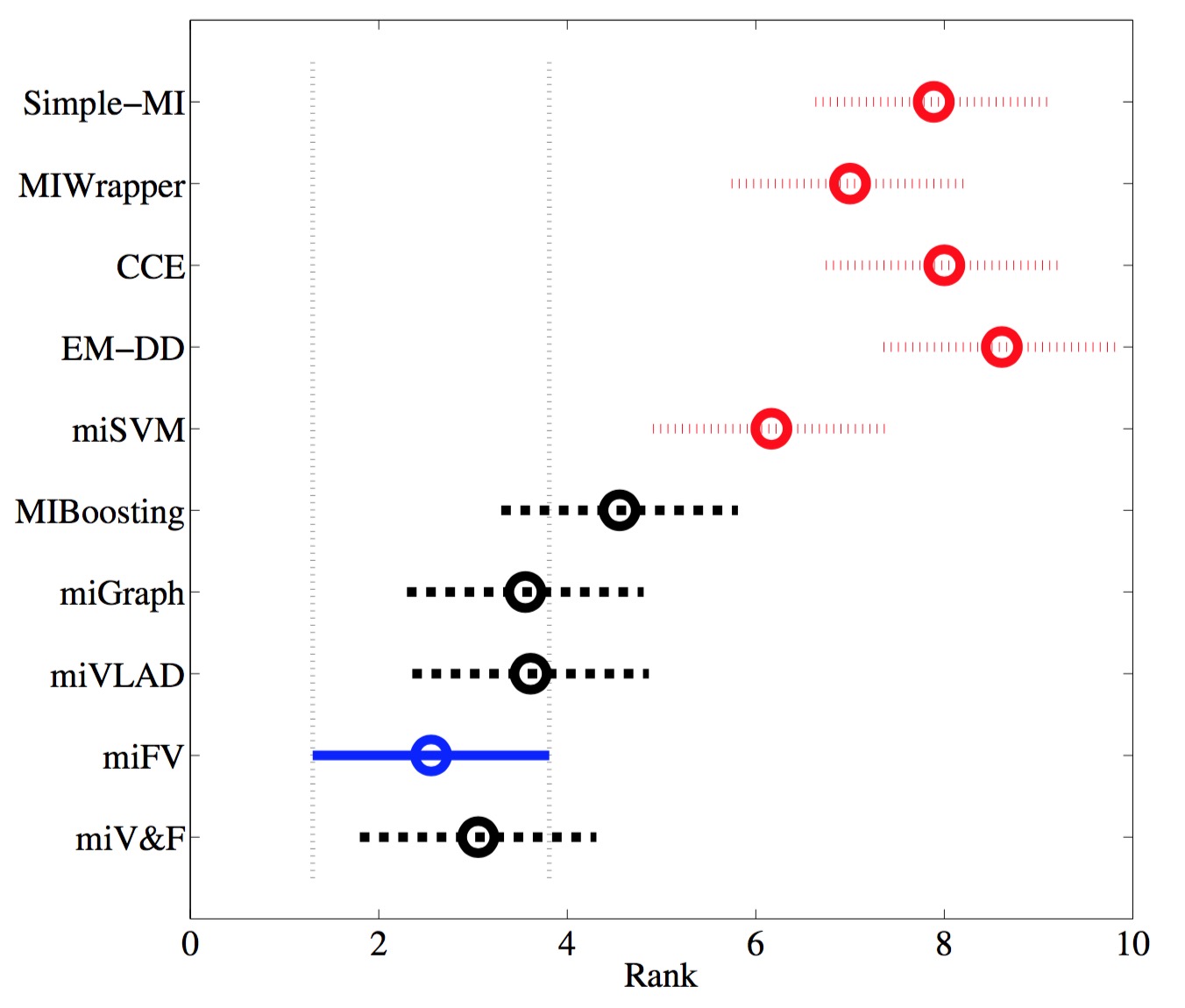 |
Friedman test results for comparing the proposed methods with other MIL algorithms on nine MIL data sets. The vertical axis indicates the MIL algorithms, and the horizontal axis indicates the rank values. The circle is the average rank for each algorithm and the bar indicates the critical values for a two-tailed test at 95% significance level. When two algorithms having non-overlapping bars, it indicates that they are significantly different. Significantly worse results are presented in dotted bars (colored in red) located on the right-hand-side of the diagram. The best results are presented in solid bars (colored in blue) on the leftmost side in the diagram. |
Efficiency Comparison
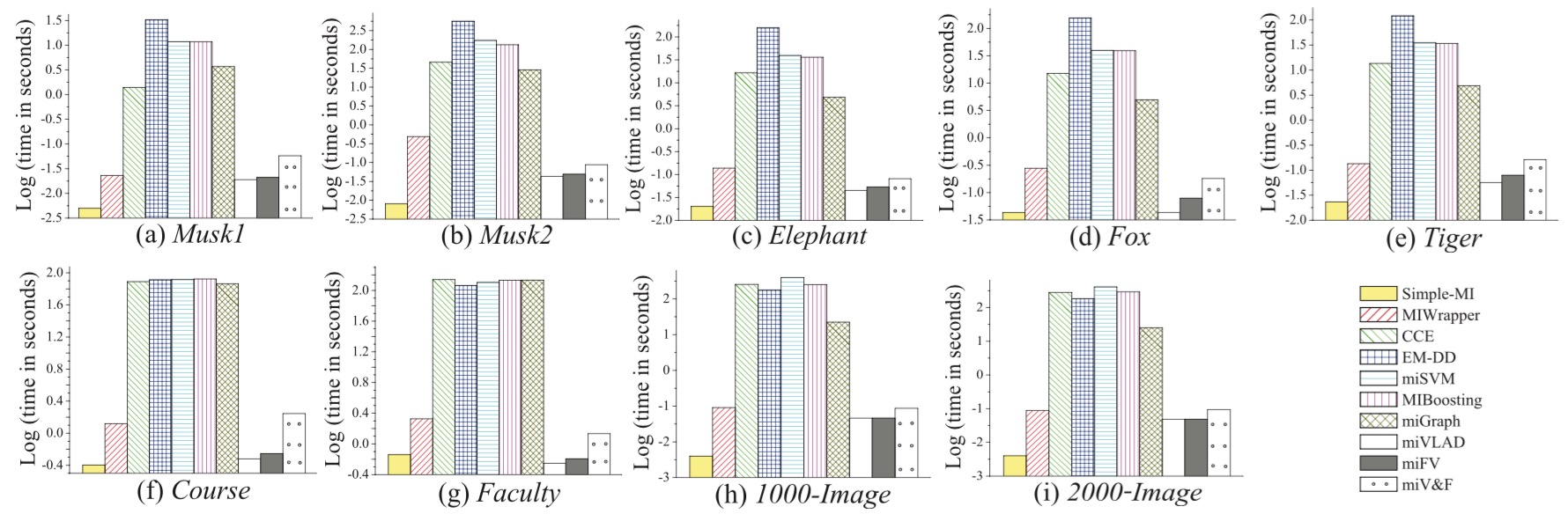 |
Comparison of mean time cost of training time on nine data sets. Note that for the first seven data sets, these results are the average time cost of ten times 10-fold cross validation. For the latter two image data sets, they are the average time cost of the rounds for one-against-one strategy. The vertical axes are shown in log-scale. The test time has the identical trends (You can refer to the TNNLS paper for more details).
Related Papers
X.-S. Wei, J. Wu, and Z.-H. Zhou. Scalable Algorithms for Multi-Instance Learning. IEEE Transactions on Neural Networks and Learning Systems (TNNLS), in press. [slide] [code]
X.-S. Wei, J. Wu, and Z.-H. Zhou. Scalable Multi-Instance Learning. In Proceedings of the 14th IEEE International Conference on Data Mining (ICDM’14), Shenzhen, China, 2014, pp.1037-1042. (Acceptance Rates: 19.53%) [slide] [code]